
Анализ выбора AI стартапов: сравнение затрат и ROI облачных и локальных развертываний GPU (данный материал является официальным контентом, предоставленным $IO для обобщающего изучения исследований)
Ниже представлено подробное разбиение затрат на облачные и локальные развертывания GPU (On-Premises).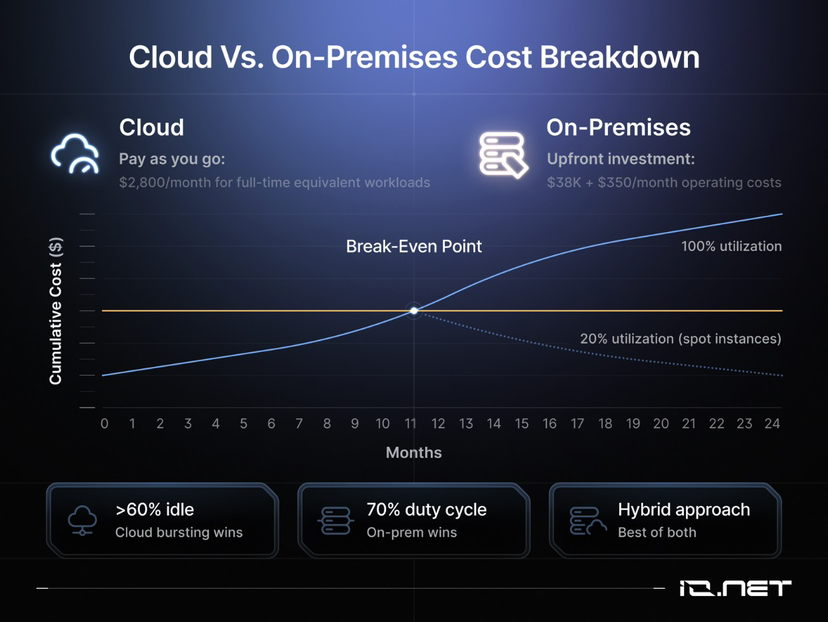
1. Сравнение данных затрат
• Локальное развертывание (On-Prem): первоначальные инвестиции в кластер GPU на 64 ядра составляют около 38 000 долларов, кроме того, ежегодно необходимо нести расходы на электроэнергию в размере около 4 200 долларов.
• Облачная аренда (Cloud): стоимость облачных ресурсов с аналогичной конфигурацией составляет около 2 800 долларов в месяц.
2. Анализ безубыточности и сценариев использования
Точка безубыточности для локального развертывания составляет 14 месяцев, но это применимо только при условии, что оборудование работает круглосуточно. Если время работы нагрузки составляет лишь 20%, использование облачных аукционных инстансов (Spot Instances) предоставляет лучшие преимущества по капитальным расходам (Capex).
3. Оркестрация ресурсов и гибкость
Оркестрация (Orchestration) является ключом к обеспечению архитектурной гибкости. Ссылаясь на типичную архитектуру финтех-компаний Fintech: использование инструментов, таких как Slurm-on-Kubernetes, для запуска чувствительных моделей локально, а при необходимости масштабирования (например, для ночных тестов) - расширение до 10,000+ облачных ядер.
4. Пороговые значения для закупок
Рекомендуется принимать решения на основе ядер-часов (Core-hours):
• Покупка оборудования: нагрузка превышает 1,200 ядер-часов/месяц.
• Аренда облака: нагрузка ниже этого значения.
5. Мониторинг использования и корректировка ресурсов
Следует записывать фактические данные использования GPU, а не полагаться на догадки:
• Если свободное время > 60%: указывает на наличие неэффективного использования аппаратных ресурсов, следует перейти в режим облачной обработки (Cloud Bursting).
• Если коэффициент загрузки (Duty Cycle) постоянно > 70%: рекомендуется приобрести оборудование или арендовать выделенные серверы (Bare Metal).
6. Стратегия масштабируемой параллельной обработки
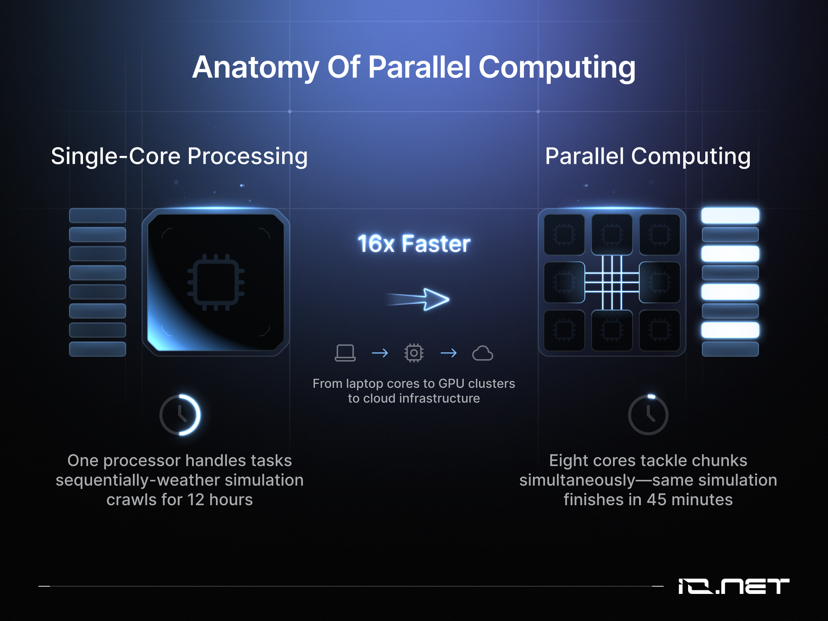
Для крупных рабочих нагрузок рекомендуется применять гибридную стратегию: сохранять базовые вычислительные мощности локально, используя децентрализованные облачные ресурсы для удовлетворения пиковых потребностей. Следует постоянно мониторить данные использования и динамически корректировать масштаб ресурсов.