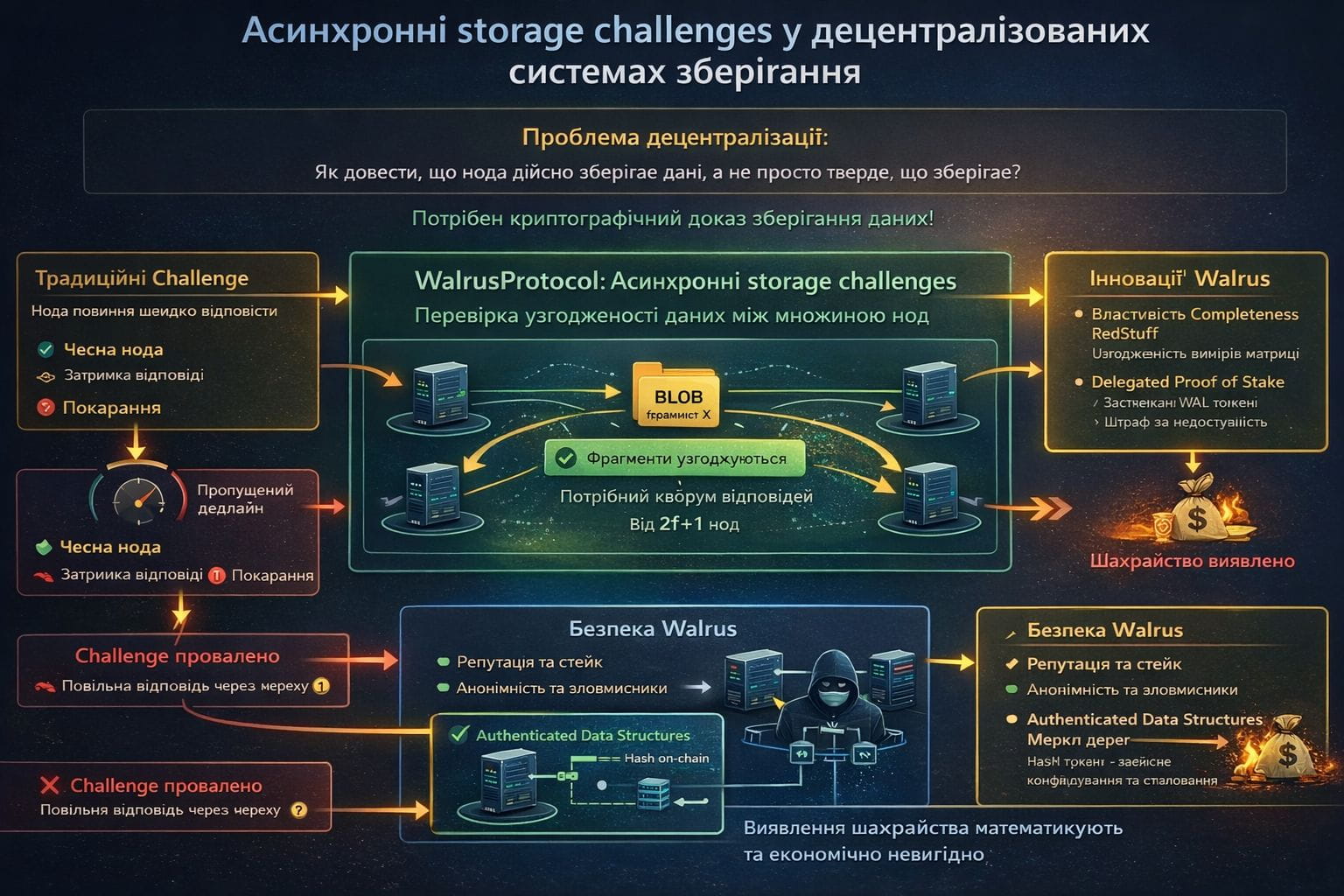
Одна з проблем, яка завжди мучила децентралізовані системи зберігання: як довести, що нода справді зберігає дані, а не просто каже, що зберігає? Централізовані сервіси типу Dropbox чи AWS можна перевірити аудитом, але в децентралізованій мережі, де ноди анонімні і потенційно зловмисні, потрібен криптографічний доказ. @Walrus 🦭/acc вирішує це через перший асинхронний протокол storage challenges, і це технічне досягнення, яке більшість людей недооцінює. Традиційні storage challenges працюють так: мережа випадково запитує ноду: "Доведи, що маєш фрагмент X", нода повинна надати криптографічний доказ за певний час. Якщо нода не відповідає або відповідає неправильно, її карають. Звучить просто, але є величезна вразливість у синхронних системах: зловмисна нода може не зберігати дані взагалі, але під час challenge швидко завантажити їх з іншої ноди і надати правильну відповідь. Або чесна нода може бути покарана через тимчасові мережеві проблеми, які затримали відповідь. $WAL використовує інший підхід, заснований на властивостях RedStuff та візантійській толерантності. Замість того щоб вимагати швидкої відповіді від конкретної ноди, система перевіряє узгодженість даних між множиною нод. Коли клієнт запитує blob, він отримує фрагменти від різних нод і перевіряє, чи вони узгоджуються з криптографічними зобов'язаннями, які були створені під час запису. Якщо фрагмент від ноди не відповідає commitment або не узгоджується з реконструкцією з інших вимірів матриці, це автоматичний доказ шахрайства. Ключова інновація тут — completeness property RedStuff. #Walrus гарантує, що кожна чесна нода може відновити будь-який фрагмент будь-якого blob, використовуючи двовимірну структуру даних. Це означає, що якщо нода A стверджує, що не має фрагмента, але інші ноди можуть довести, що цей фрагмент можна реконструювати з наявних даних, нода A викривається як шахрай. Немає можливості сказати "я втратив дані" чи "мережа була повільна" — математика не дозволяє брехати. Протокол працює асинхронно, що означає відсутність припущень про час доставки повідомлень. Challenge не має дедлайну — система просто чекає кворуму відповідей від 2f+1 нод і перевіряє узгодженість. Якщо частина нод відповідає швидко, а частина повільно через мережеві проблеми, це не проблема. Важлива не швидкість, а правильність. Це робить систему стійкою до DDoS-атак, які могли б затримати відповіді, та до спроб зловмисників маніпулювати часом. Що відбувається з нодами, які провалюють challenges? У поточній реалізації Walrus використовує модель Delegated Proof of Stake, де WAL токени застейкані з нодами. Якщо нода систематично провалює перевірки доступності, її стейк може бути slashed — частково конфіскований і спалений. Це створює економічний стимул зберігати дані чесно: вартість шахрайства перевищує потенційну вигоду від економії на зберіганні. А чесні ноди отримують винагороди в WAL наприкінці кожної епохи за надійне зберігання і обслуговування даних. Система вирівнює стимули так, що раціональна поведінка — це чесна поведінка. Є ще один цікавий аспект: Walrus використовує authenticated data structures — Merkle trees з криптографічними зобов'язаннями, які створюються під час запису і зберігаються ончейн на Sui. Це означає, що клієнт може перевірити цілісність даних без довіри до нод: він просто порівнює отримані дані з хешем у блокчейні. Якщо хеші не збігаються, дані скомпрометовані, і клієнт може вимагати повторного завантаження від інших нод. Немає можливості підсунути фальшиві дані, бо блокчейн служить незмінним джерелом істини. І коли дивишся на експериментальні результати команди, бачиш, що ці механізми працюють навіть при високому навантаженні — тисячі запитів на секунду з latency у мілісекундах.
Мои мысли: Проблемы хранения в Walrus показывают, что настоящая безопасность заключается не в том, чтобы полагаться на честность участников, а в том, чтобы сделать нечестность математически обнаружимой и экономически невыгодной. Это инженерный подход, который превращает проблему доверия в проблему стимулов, и именно так должна работать децентрализация.