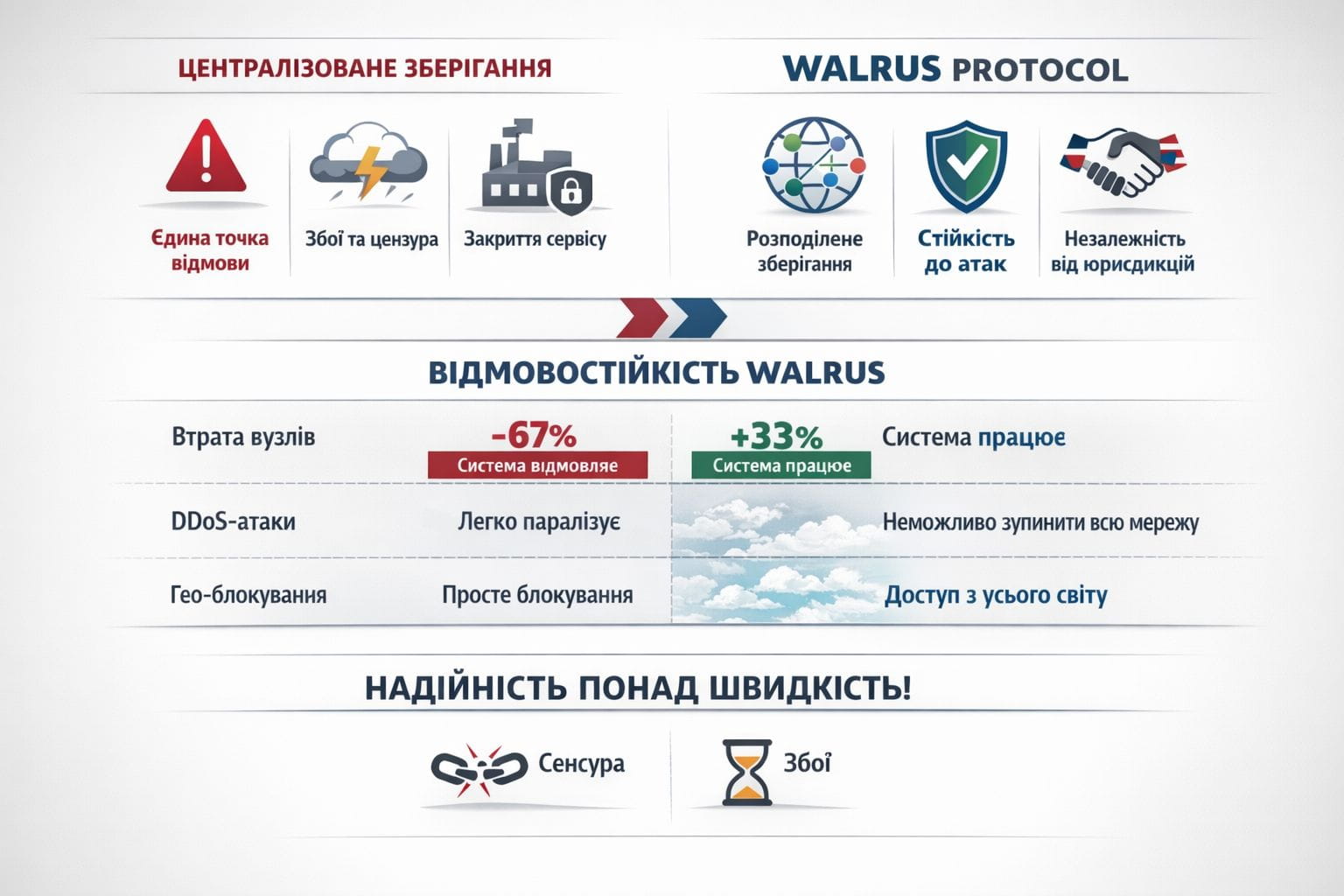
В мире технологий царит культ скорости. Каждый новый проект кричит о миллисекундах латентности, о тысячах транзакций в секунду, о мгновенной загрузке. И когда смотришь на @Walrus 🦭/acc , можно подумать, что скорость здесь тоже главное. Но на самом деле ключевая ценность Walrus не в том, насколько быстро он работает, а в том, что он продолжает работать независимо от обстоятельств. Это фундаментальное различие между игрушкой для демо и инструментом, которому можно доверить критические данные. Давайте посмотрим на историю централизованных сервисов. Amazon S3 падал несколько раз за последние годы, и каждый раз это приводило к массовым сбоям сайтов и приложений по всему интернету. Google Cloud имел инциденты, когда целые регионы были недоступны часами. Это не провалы отдельных компаний – это врожденная слабость централизованных систем. Одна точка отказа, как бы она ни была защищена резервированием, остается уязвимой к DDoS-атакам, ошибкам в конфигурации, физическим сбоям оборудования. Walrus строится на принципиально другой философии: отсутствие единой точки отказа не на уровне деклараций, а на уровне архитектуры. Файл не просто копируется на несколько серверов – он разбивается на фрагменты так, что даже потеря двух третей узлов не делает его недоступным. Это не теоретическая возможность, это математическая гарантия, заложенная в стиральное кодирование. Если протокол настроен на восстановление из 33% фрагментов, то система продолжает работать даже когда 67% инфраструктуры недоступны. Попробуйте найти централизованный сервис, который выдержит такое. Но отказоустойчивость – это не только про технические сбои. Это про геополитические риски, про цензуру, про ситуации, когда доступ к данным становится вопросом не технологий, а политики. Когда правительство блокирует IP-адреса, когда провайдер закрывает аккаунт за подозрительную активность, когда хостинг решает, что ваш контент нарушает их условия использования. Во всех этих случаях централизованное хранение превращается в уязвимость. Walrus распределяет файлы географически и юридически – фрагменты хранятся в разных странах, под разными юрисдикциями, на оборудовании разных операторов. Заблокировать доступ ко всем одновременно практически невозможно. Еще один аспект отказоустойчивости – долговечность данных. Централизованные провайдеры могут обанкротиться, изменить бизнес-модель, закрыть сервис. Помните сколько файлохостингов исчезло за последние двадцать лет, забрав с собой терабайты данных? Walrus не зависит от решения одной компании. Если кто-то из операторов узлов выйдет из сети, его место займут другие – протокол создает экономические стимулы для этого через вознаграждения в $WAL. Данные живут до тех пор, пока кто-то платит за их хранение, и эта оплата распределяется между участниками сети, а не оседает в кармане корпорации. Отказоустойчивость также означает устойчивость к атакам. DDoS на централизованный сервер может парализовать его на часы. Атака на распределенную сеть Walrus требует одновременной перегрузки сотен узлов в различных частях мира – задача настолько сложная и дорогая, что теряет экономический смысл. Даже если атакуют отдельные узлы, система автоматически переключается на другие, и пользователи даже не замечают проблемы. Это принципиально другой уровень защищенности от того, что предлагают традиционные решения. #Walrus
Когда я думаю о том, что на самом деле важно в хранении данных, я понимаю: скорость приятна, но отказоустойчивость критична. Можно подождать лишнюю секунду на загрузку файла, но невозможно вернуть утерянные данные или получить доступ к заблокированному контенту. Walrus выбирает правильный приоритет – надежность превыше всего. Мне кажется, именно это делает его серьезным решением для тех, кто понимает ценность данных и не готов ставить их под риск ради красивых цифр в маркетинговых презентациях.