
Storage failures rarely happen in dramatic ways. There’s no headline. No exploit alert.
Instead, they show up quietly.
An NFT image doesn’t load. A game asset disappears. A profile page feels incomplete. Each incident is small, but together they erode confidence.
@Walrus 🦭/acc exists to address this exact problem.
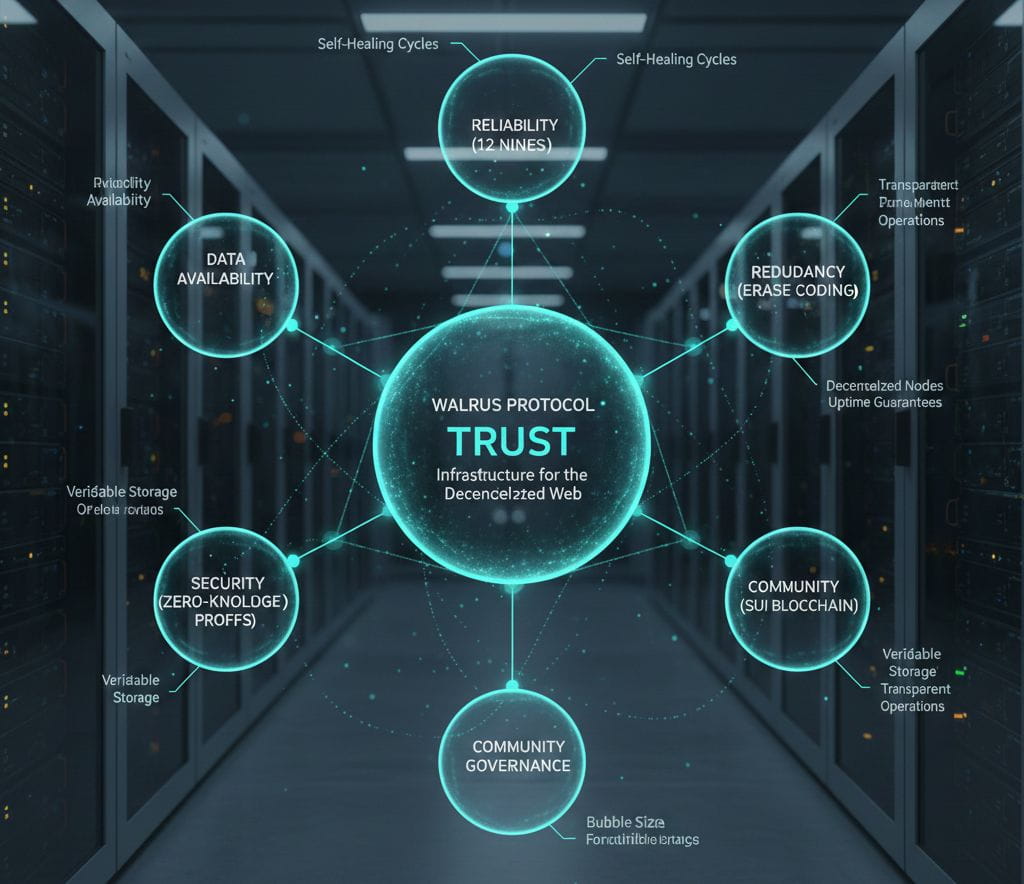
Rather than assuming nodes will remain online forever, Walrus assumes they won’t. Its architecture is designed around churn — nodes joining, leaving, failing, or losing incentives.
Data is split, encoded, and distributed so the network can tolerate failure without losing availability. Recovery isn’t an emergency process. It’s part of the design.
This matters because most applications don’t die from a single catastrophic event. They die from accumulating small reliability issues.
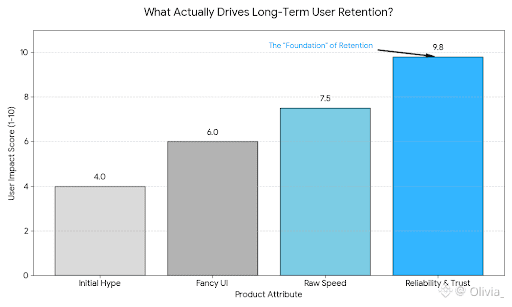
#walrus reduces that risk by making data availability predictable and resilient, even under imperfect conditions.
In the long run, reliable storage isn’t a feature.
It’s the difference between trust and abandonment.

