
Everyone talks about Walrus features in isolation: self-healing, low overhead, trustless verification. But let's get real: what matters is how these pieces work together end-to-end. The flow from encoding to proof-of-availability is where the elegance shows. This is infrastructure that's actually thought through.
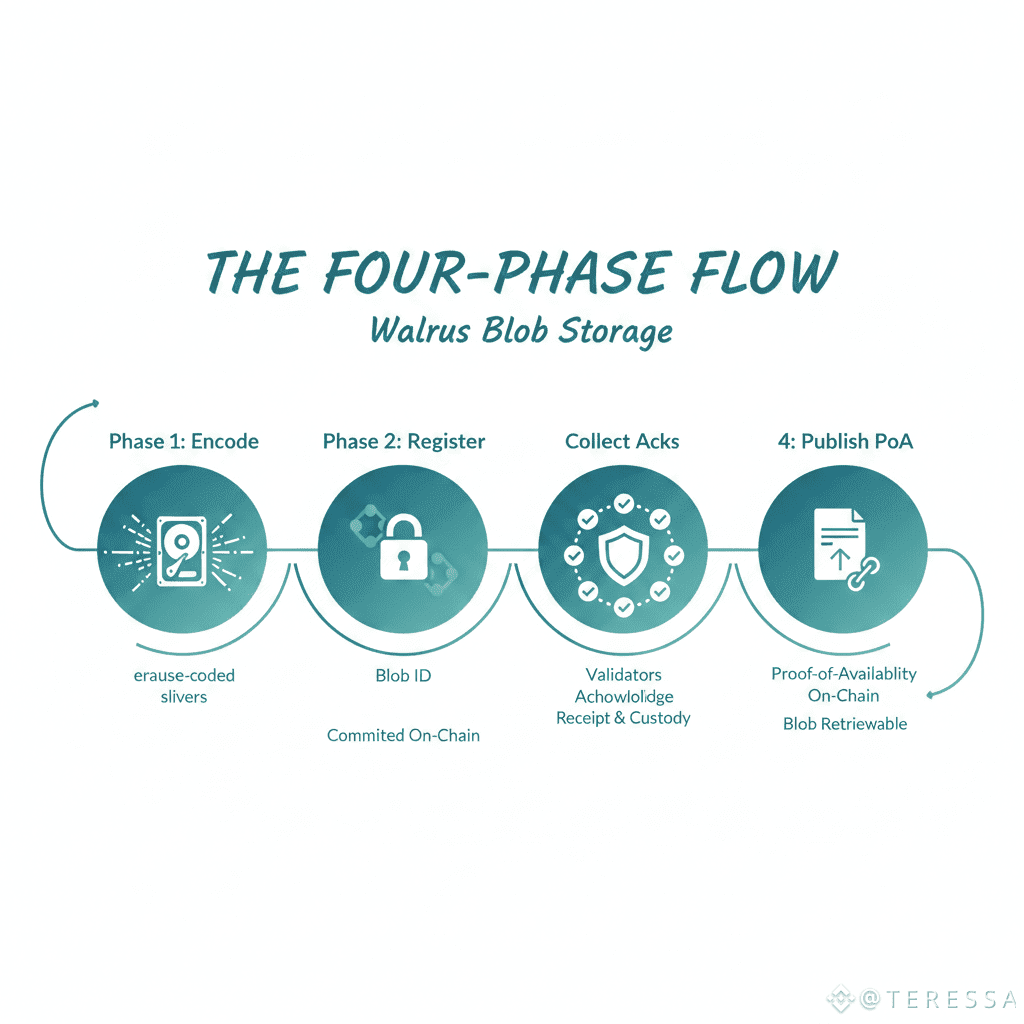
The Four-Phase Flow
Walrus blob storage happens in four elegant phases:
Phase 1: Encode - Your data becomes erasure-coded slivers
Phase 2: Register - The blob gets a Blob ID and is committed on-chain
Phase 3: Collect Acks - Validators acknowledge receipt and custody
Phase 4: Publish PoA - Proof-of-availability goes on-chain, blob is retrievable
Each phase serves a specific purpose. Together they create a system where data is simultaneously stored, verified, committed, and provably available.
Most storage systems shuffle these phases around or combine them badly. Walrus's ordering is deliberate.
Phase 1: Encode Your Data
The flow starts with encoding. You have a blob. Walrus applies erasure coding to create n slivers from k+1 original data.
Here's what happens:
The original blob is sharded into pieces
Erasure coding creates slivers that are individually useless but collectively complete
The encoding produces a deterministic commitment
The commitment is mathematically unique to this blob, this encoding scheme, this set of parameters. You can't create a different blob that produces the same commitment. The encoding is now the source of truth.
This phase happens locally—no network involvement. Encoding is fast. Commit is ready immediately.
Phase 2: Register on-Chain
Once encoded, the blob needs registration. This creates the Blob ID (Hash(data || encoding || params)) and submits it on-chain.
Registration serves multiple purposes simultaneously:
First, it creates a single source of truth. The blockchain proves the blob exists and specifies exactly how it's encoded.
Second, it anchors availability. Everything downstream refers back to this registration. On-chain commitment is permanent and verifiable.
Third, it enables parallelization. While the blob is dispersing to validators, registration is happening on-chain. Both can proceed concurrently.
Fourth, it creates economic accountability. Validators who commit to storing this blob are making an on-chain promise. Breaking the promise has on-chain consequences.
The registration is small—constant size regardless of blob size. It's cheap to post. It's fast to verify.
Phase 3: Collect Acks
Phase 2 doesn't wait for Phase 3. While the blob is dispersing to validators, they're acknowledging receipt.
Here's how it works:
The custodian committee for this blob receives slivers. Each validator cryptographically signs/commits to:
Having received the blob
Having the slivers they're responsible for
Agreeing on the encoding
Committing to store through the designated epoch
These acks are collected in parallel. As acks arrive, the system batches them.
Critically: acks don't require coordination. Each validator creates an independent ack. They don't need to wait for others or achieve consensus. Their individual acks naturally create evidence of custody.
This parallelization is crucial for performance. You're not waiting for validators to talk to each other. You're collecting independent evidence of receipt.
Phase 4: Publish PoA
Once you have sufficient acks—enough to prove the blob is stored safely despite Byzantine faults—publish proof-of-availability on-chain.
The PoA is:
Small (aggregated acks are constant size)
Verifiable (anyone can check acks against the Blob ID)
Permanent (it's on-chain)
Economic (validators lose stake if they claimed custody and didn't provide it)
PoA publication makes the blob retrievable. Clients can now request it with confidence. The on-chain proof guarantees it exists.
Why This Ordering Is Elegant
Encode → Register → Collect Acks → Publish PoA isn't arbitrary. Each phase builds on the previous:
Encoding produces the commitment. Registration anchors it. Acks prove custody. PoA makes it retrievable.
Each phase can happen partially in parallel, but they have a logical order. You can't claim acks before you know the encoding. You can't publish PoA before you have acks.
Traditional systems either:
Do phases sequentially (slow)
Do them in parallel but create coordination overhead (complicated)
Skip phases entirely (unsafe)
Walrus finds the sweet spot: phases happen mostly in parallel with minimal coordination.
Latency Breakdown
Encoding: milliseconds (local)
Registration: one block latency (state on-chain)
Ack collection: one epoch (slivers dispersing, validators responding)
PoA publication: one block latency (aggregated proof on-chain)
Total: roughly one epoch + two blocks. That's seconds to minutes depending on the system. Not milliseconds. But also not the seconds-to-minutes of sequential approaches.
The parallel collection phase is what makes this fast.
What Parallelization Enables
Because Ack collection happens while slivers are dispersing, you get:
Slivers propagating to validators
Validators receiving and acknowledging
Acks aggregating
System preparing PoA
All happening concurrently. Network latency is hidden by validator computation. Validator computation is hidden by network transfer.
This is pipeline parallelism. Each phase overlaps with the next.
Verification at Each Phase
The beauty of this flow is that verification happens at multiple points:
After Encoding: Commitment is computed. Data matches commitment or doesn't.
After Registration: Blob ID is on-chain. It's immutable and verifiable.
After Acks: Validators have signed custody. Their acks are public.
After PoA: Anyone can verify the proof against the Blob ID.
Each verification point is independent. You can check any phase without trusting others.
Economic Incentives at Each Phase
Register: Validators haven't committed yet. No cost.
Collect Acks: Validators claim custody. If they're lying, they lose stake when PoA comes due.
Publish PoA: Validators have to deliver. Blob must be retrievable or they lose stake.
The economic incentives escalate through the phases. Early phases are cheap to claim. Later phases have real economic consequences.
This creates self-selection: honest validators commit. Dishonest ones realize they'll lose money.
Handling Byzantine Scenarios
What happens if a validator claims custody and disappears before PoA publication?
Other validators notice. The ack from the missing validator is still valid (it was published). But when PoA comes due, that validator can't provide the blob.
The system detects the failure and triggers repair. Remaining validators re-encode the sliver the missing validator had. The repair completes before PoA deadline.
From the outside: the blob remains available. The Byzantine validator is penalized. The system heals automatically.
Rollup Integration
For rollups using Walrus:
Commit batch to rollup state
Walrus encode and register happens in parallel
By the time rollup state is finalized, PoA is available
Rollup chain can reference the PoA directly
The whole flow is concurrent. Rollup posts data. Walrus proves availability simultaneously.
Archive Integration
For archives storing forever:
Data arrives
Walrus phases start
PoA comes online
Data is now permanently available
Validators are paid over multiple epochs for custody
The flow remains the same. Storage duration extends. Economics adjust.
Read Integration
When someone reads a blob:
They check on-chain PoA
PoA proves custodian committee exists
They query committee members for slivers
They collect secondary slivers for verification
They verify through re-encoding
The PoA gives them confidence that the blob exists and is stored. The read path verifies it's authentic.
The Psychological Flow
There's something satisfying about this flow:
You have data
You encode it
The commitment is immutable
Validators take responsibility
The proof is permanent
Data is forever retrievable
Each step is visible. You can follow the blob through the system. You can verify at any point.
This transparency builds confidence. You're not betting on a black box. You're watching the process happen on-chain.
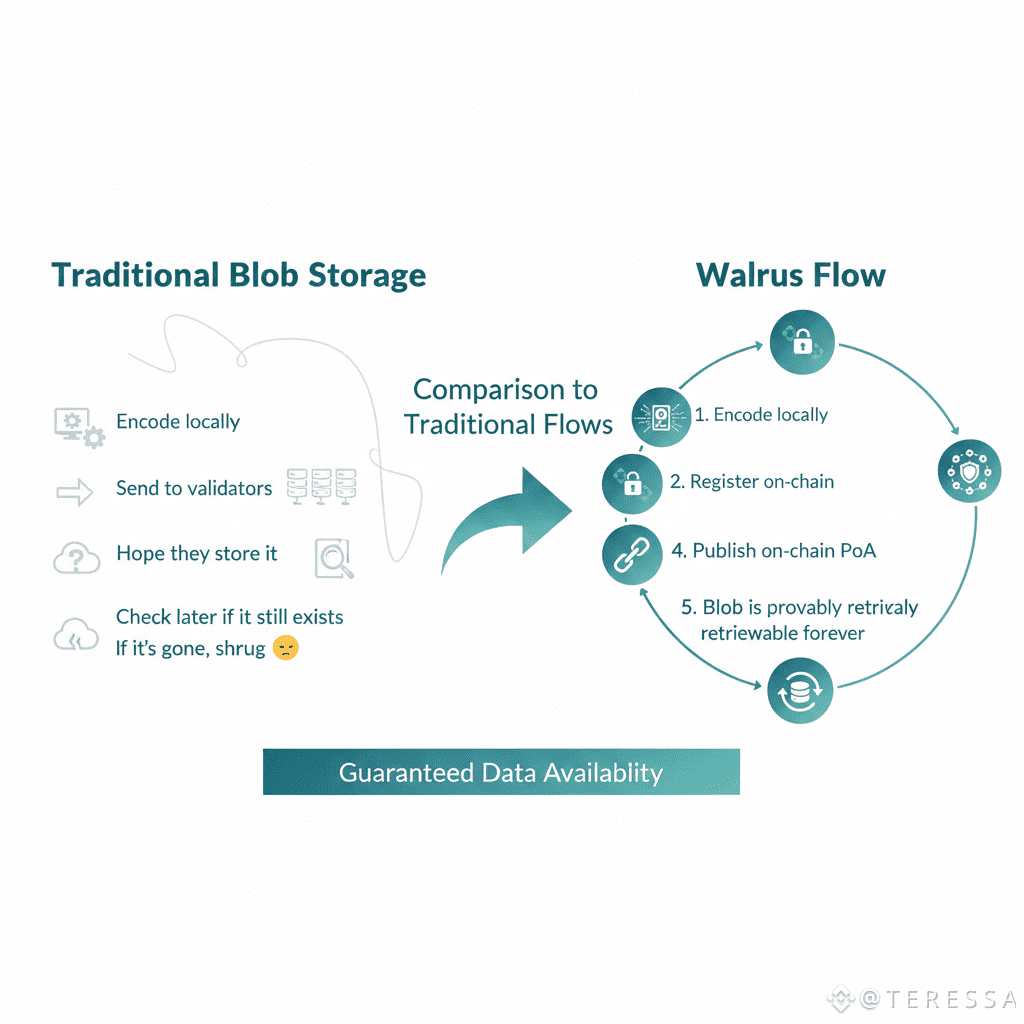
Comparison to Traditional Flows
Traditional blob storage:
Encode locally
Send to validators
Hope they store it
Check later if it still exists
If it's gone, shrug
Walrus flow:
Encode locally
Register on-chain
Collect on-chain acks
Publish on-chain PoA
Blob is provably retrievable forever
The difference is total visibility and accountability.
@Walrus 🦭/acc end-to-end flow—Encode → Register → Collect Acks → Publish PoA—represents mature infrastructure design. Each phase serves a purpose. Phases happen in parallel where possible. Verification is available at every step. Economic incentives escalate appropriately. The result is a system where data is simultaneously encoded, registered, acknowledged, and provably available—all within one epoch.
For applications needing certainty that their data exists and is retrievable, this is foundational. You're not trusting validators. You're following the proof through every phase. Walrus makes the entire flow transparent, verifiable, and economically incentivized for correctness. That's infrastructure built right.

