

Nobody pages you because a blob "vanished."
They page you because the blob is there and still won't load.
On Walrus, that's the ugly middle state teams hate... not loss, not outage. A moving target. Same blob ID, different serving path, and a user who does not care that the network is mid rotation at an epoch boundary. They just hit refresh again. And again.
This isn't the poetic idea of Walrus' availability. It's continuity while the map is shifting under your feet.
Shards are where they should be, on paper. Walrus Erasure coding still makes reconstruction possible, on paper. The onchain side still has the claim. The proof-of-availability record might even be clean for the window you paid for.
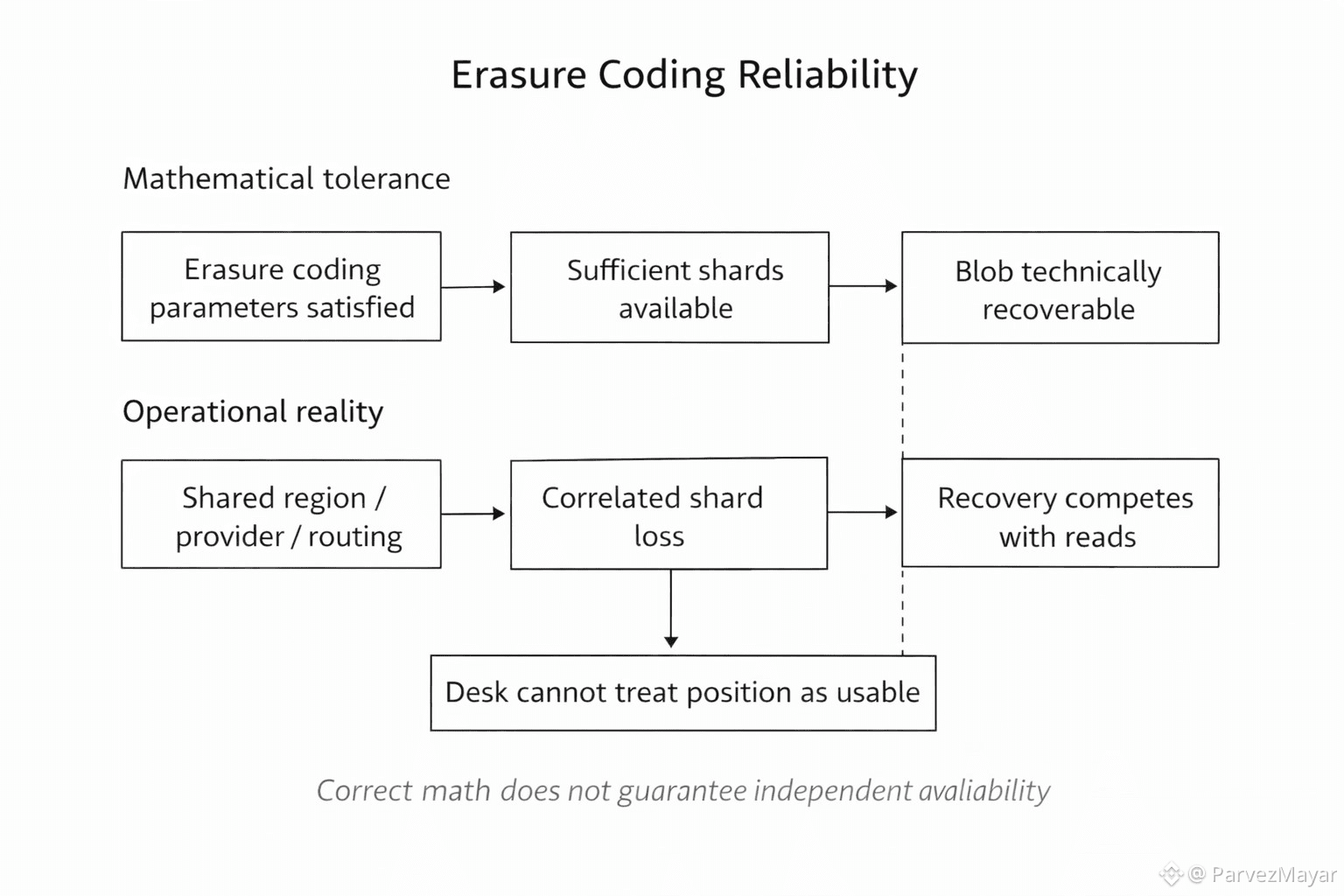
And the fetch still stalls. p95 doubles before anyone wants to say it out loud.
Because what slips first isn't the data. It's the handoff. The coordination that was supposed to be boring.
A few nodes slow down. A few peers are "up" but effectively asleep. The fastest path to the pieces changes. Duty assignments shift. Repair work starts competing with live reads at the exact moment users spike retries because the UI looks stuck.
That's when "mostly fine" starts billing you.
You can watch the cascade in the most boring places:
A wallet retries because it didn't get a response in time. The frontend retries because it assumes the request was dropped. A CDN edge retries because it thinks it's helping... and now you're chasing ghosts.
Now you've turned a slightly degraded path into load. Not malicious load. Normal-user load. The kind nobody wants to blame.
On Walrus Repairs aren't free either. Repair bandwidth is real bandwidth. If the network is rebuilding redundancy while reads hammer the same resources, someone has to choose what gets priority. Serve through the boundary, or heal the boundary first.
Teams patch fast. Of course they do.
They add caching rules and call them temporary. They prefetch "hot" blobs ahead of known churn windows. They quietly add a fallback path so the user never touches the wobbly route again.
And here's the part nobody writes in docs: those patches don't get removed. They become the architecture.
Walrus can still be the backstop. The settlement layer for claims. The audit trail that says "this obligation cleared in this window." But if the live path keeps wobbling at the exact moments responsibility is moving, builders will route around it without calling it a philosophy.
They'll call it: "I'm not getting paged again."
Next week it "works." Nobody removes the fallback.


