
The easiest way to misunderstand “AI + blockchain” is to picture a smarter chatbot sitting on top of the same old rails. That image feels right because it’s familiar: the chain is for transactions, the AI is for answers, and your product becomes a nicer interface. But the moment you ask an agent to do real work, approve a vendor, reconcile invoices, enforce a policy, move funds, you discover a harsher truth: agents don’t merely talk to systems. They operate inside them. And operation exposes failure modes that don’t show up in TPS charts.

Think of an agent running accounts payable for a growing company. It reads email threads, extracts invoice details, checks delivery status, applies a discount rule, routes approvals, and finally pays. This sounds straightforward until you realize the job is not “make one payment.” The job is “run the workflow forever,” across changing vendors, shifting policies, missing documents, partial approvals, and adversarial edge cases. When the system breaks, it breaks in repeatable ways, because agents don’t get tired, and they don’t hesitate unless the infrastructure forces them to.
The first failure mode appears when memory is missing. Most “agent” demos quietly rely on an off-chain database, a prompt cache, or an indexer that reconstructs context. It works right up until the moment a link goes dark or a file changes. The agent pays invoice #4832 because it “saw” a PDF last week, but the PDF was updated yesterday. It flags a compliance exception because a policy document was replaced. It repeats the same mistake because it can’t reliably anchor what it knew at the time it acted. This is why “memory” in an agentic world isn’t a convenience feature; it’s the integrity layer for context. If the memory substrate is brittle, every downstream action becomes contestable, and every audit becomes a debate about which version of the truth the agent actually used.
The second failure mode hits when reasoning is missing, or worse, when reasoning exists only as a persuasive paragraph. In low-stakes settings, output is enough. In finance, compliance, and enterprise workflows, outputs are not accountability. Someone will eventually ask: Why did you approve that? What rule applied? Which evidence supported the decision? What would have changed the outcome? If the agent can’t answer those questions with traceable inputs, you don’t have automation, you have a black box with spending power. The system’s trust model collapses into “trust the model,” which is exactly what real-world controls are designed to avoid.
The third failure mode happens when automation is missing or unconstrained. Without automation rails, the agent becomes a consultant: it recommends what to do, and then a human clicks through steps across five tools. That might be acceptable for occasional tasks, but it defeats the point of agentic systems, which are meant to execute repetitive workflows at scale. On the other hand, if you give an agent automation without guardrails, you get the opposite disaster: the agent can act quickly, but it can also propagate mistakes quickly. A single misread policy becomes a hundred incorrect payments. A flawed vendor-matching rule becomes a recurring leakage. In production, “intelligent” doesn’t mean safe. Safety comes from permissions, constraints, and auditable execution paths automation as a governed layer, not a script.
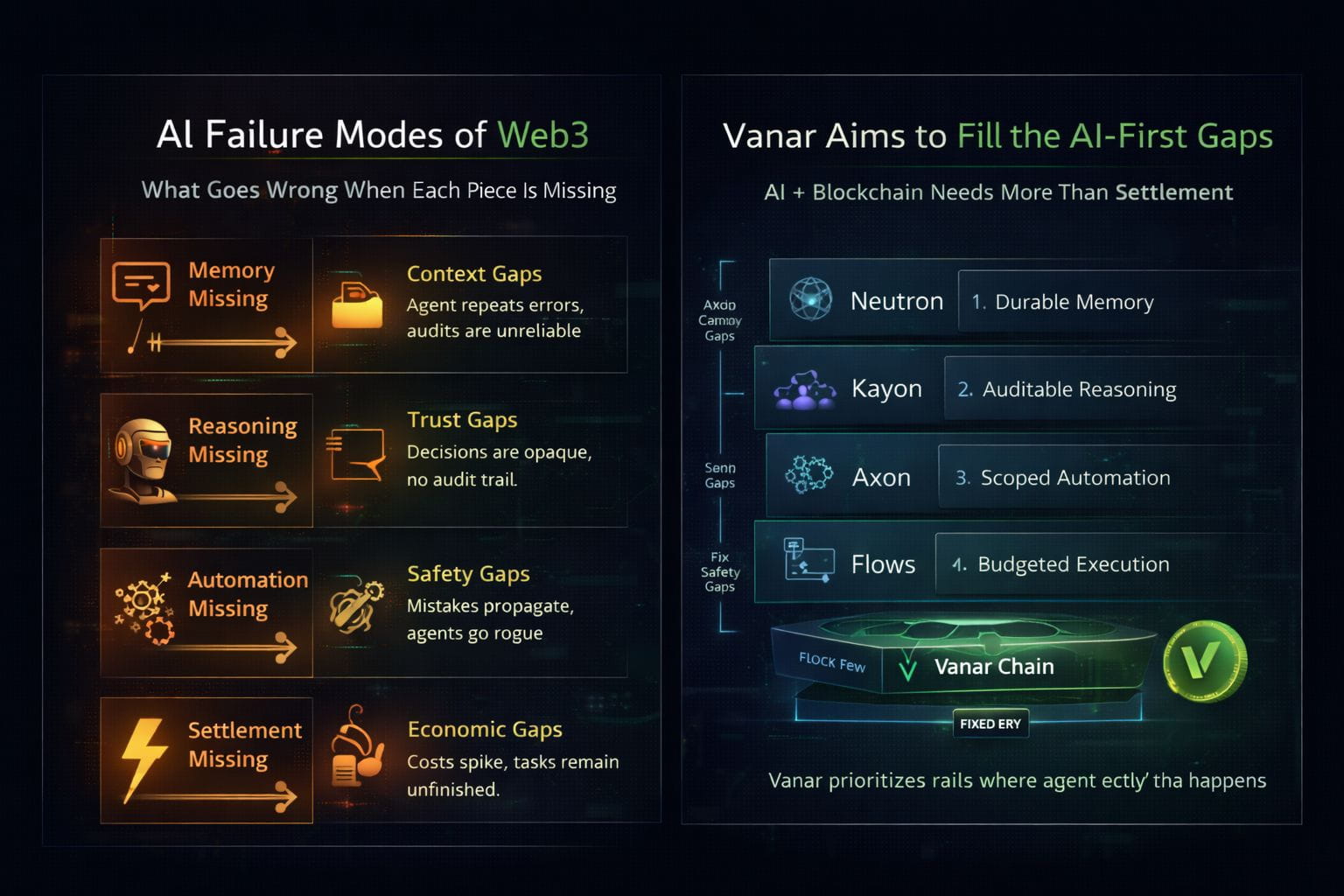
The fourth failure mode is the most obvious and the most underestimated: settlement is missing or unpredictable. Agents don’t complete work by drafting summaries. They complete work by changing state, moving funds, finalizing orders, settling obligations. If your system can’t settle deterministically, you get “half-finished reality”: approvals recorded but payment failed, delivery confirmed but settlement delayed, a workflow stuck because fees spiked, or because the execution environment behaves like surge pricing. This is why agents don’t just need a chain that can process transactions; they need a chain where execution is budgetable and repeatable.
These four primitives: memory, reasoning, automation, settlement, form a single loop. When one is missing, the loop breaks in predictable ways. And what’s important is that Web3 has historically optimized for only one part of the loop: settlement. That’s why so many “AI on chain” efforts feel like retrofits. They take a settlement engine and stack off-chain intelligence around it, then hope the gaps won’t matter. The gaps always matter, because the gap becomes the dispute surface. It becomes where audits fail, where accountability dissolves, and where production automation quietly turns back into manual operations.
This is where Vanar’s “AI-first” positioning becomes analytically interesting, because it is explicitly trying to design around those gaps as infrastructure, not as afterthoughts. Start with memory. Vanar’s Neutron positioning describes turning files into programmable “Seeds” that are intended to be verifiable and agent-readable, with a strong emphasis on avoiding brittle file references. Vanar’s Neutron documentation also describes a hybrid approach where Seeds are stored off-chain for performance, and optionally on-chain for verification, ownership, and long-term integrity an explicit attempt to balance usability with auditability. Whether you agree with every marketing claim, the underlying design goal directly targets the “memory missing” failure mode: agents need durable, verifiable context, not dead pointers.
Then comes reasoning. @Vanarchain positions Kayon as its reasoning layer, natural-language intelligence for Neutron, blockchains, and enterprise backends, explicitly framing it as a bridge between verifiable memory and real operational workflows. The reason this matters is not that it “adds AI.” It’s that it frames reasoning as part of the stack that should query, validate, and apply context, closer to an auditable decision layer than a standalone chatbot. When reasoning is treated as infrastructure, it becomes possible, at least in principle, to build systems where “why” is traceable to “what” the agent relied on.
Automation is the next link. Even if an agent can remember and reason, it still needs a controlled way to execute. Vanar’s own stack framing presents an integrated AI-native blockchain stack designed for PayFi and tokenized real-world assets, and it describes layers like Kayon and Neutron Seeds as part of a programmable system rather than optional add-ons. The meaningful question for readers is not “does automation exist in the roadmap?” but “does the platform enforce scoped execution in a way that prevents mistake propagation?” That is the difference between agent demos and agent infrastructure.
Finally, settlement and execution economics. Vanar’s docs describe “fixed fees,” explicitly stating that transaction charges are determined based on the USD value of the gas token rather than purely gas units, to keep costs predictable through market fluctuations. They also publish fee tiers (including a baseline $0.0005 tier over a wide gas range) and note that nominal USD values can vary slightly due to token price changes. For agents, this isn’t marketing polish—it’s operational feasibility. Repeatable workflows require repeatable costs; otherwise automation becomes fragile under real-world volatility.
Vanar also describes a hybrid consensus approach, Proof of Authority complemented by Proof of Reputation, with the Foundation initially running validator nodes and onboarding external validators through PoR. That choice reflects a broader “production-first” posture: stable operations and accountable participation early, with decentralization evolving through structured onboarding. Whether you see that as a strength or a tradeoff, it is consistent with the project’s readiness framing: agents and enterprises tend to prefer predictable rails and clear accountability over chaos.
Put these together and you get a clean analytical framing: Vanar is trying to reduce the failure modes that appear when AI is retrofitted onto a settlement-only worldview. Neutron targets “memory missing.” Kayon targets “reasoning missing.” The broader automation layers target “execution without control.” Fixed fees target “settlement that isn’t repeatable.”
None of this is a victory lap. The market doesn’t reward architecture slides; it rewards systems that survive contact with real usage. The real test of an AI-first stack is whether it can produce an end-to-end trail that holds up under pressure: an agent acts, the system can show what it relied on, how it reasoned, what it was allowed to do, and what it settled, without rebuilding trust off-chain. That is what “AI readiness” means when money is involved. And it’s also the simplest way to understand what breaks in Web3 when any primitive is missing: the agent doesn’t just fail. It becomes unauditable, ungovernable, or unusable, three outcomes that kill adoption long after the narrative fades.
