
@Walrus 🦭/acc “Blob storage” used to feel like a back-office term—important, but rarely discussed outside infra circles. That changed fast once Ethereum shipped Dencun on March 13, 2024 and made blob-carrying transactions (EIP-4844) the normal way for rollups to publish temporary data. Suddenly, “data availability” wasn’t academic; it was a cost line item and a product constraint people could finally feel.
Walrus is one of the more concrete answers to the next question teams keep asking: what about the data that isn’t supposed to disappear in a couple of weeks, the stuff you need to keep fetching and proving hasn’t been quietly swapped out? Walrus is a decentralized blob storage protocol coordinated through Sui, and it launched on mainnet on March 27, 2025. The part that matters for builders is not the label “decentralized,” but the operational habit it forces: storage is treated as a workflow with verifiable checkpoints, not a hope-and-pray upload.
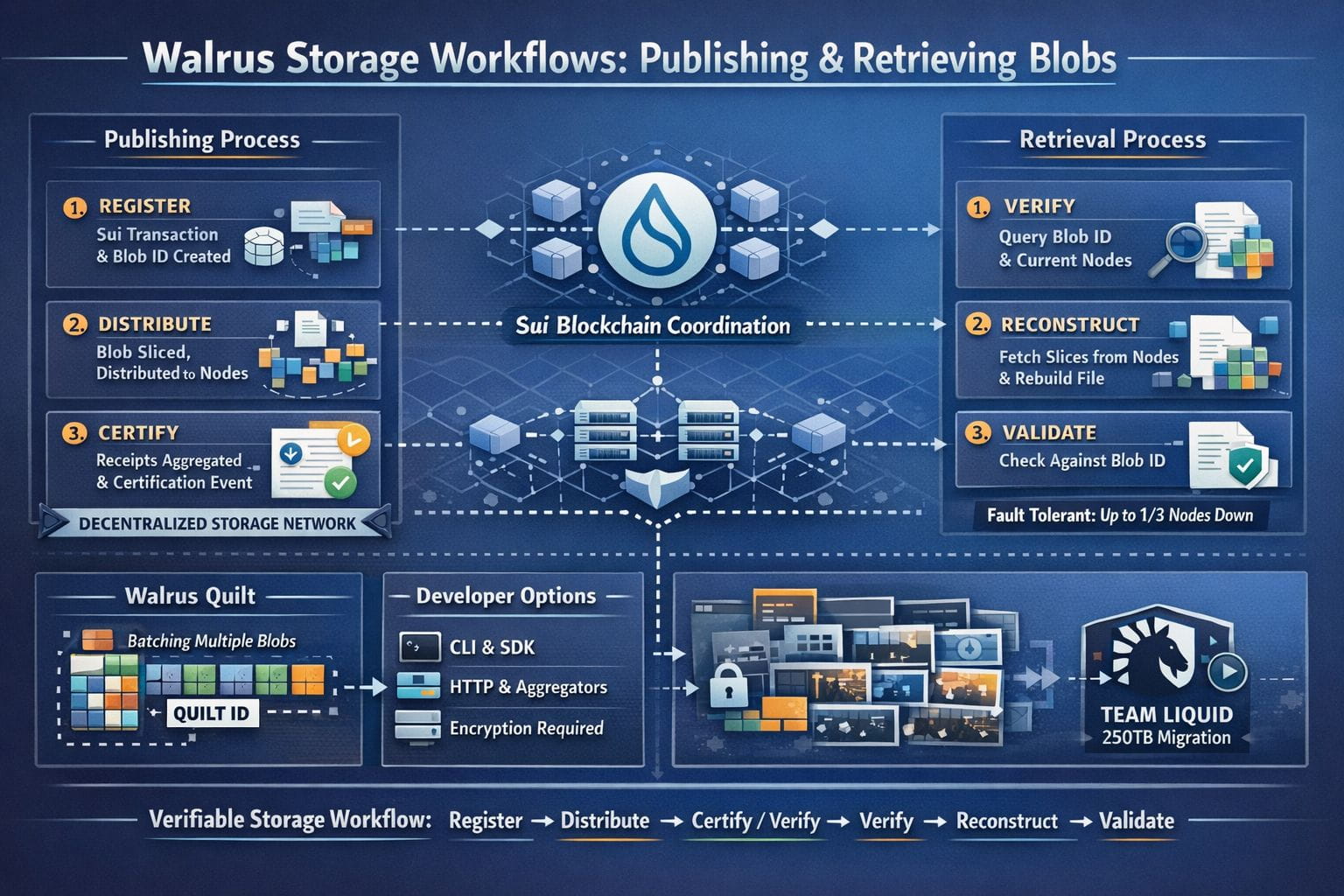
Publishing to Walrus isn’t one big “upload” button so much as three steps that have to happen in order: register, distribute, certify. The client starts by encoding the file and computing a blob ID from the content and the Walrus configuration. That ID isn’t a label you invent—it’s a fingerprint of the data—so two identical files end up with the same ID every time. You can even compute it locally with the walrus blob-id command before you store anything, which is a small detail that changes how you reason about deduplication and references.
Then comes the part that makes Walrus feel “protocol-ish” rather than “API-ish.” To store, you execute a Sui transaction that purchases storage from the system object and registers that blob ID as occupying it. The client returns the Sui blob object ID, and the chain becomes the coordination layer for what happens next. After that, the encoded file is split into many small slices (Walrus calls them slivers) and distributed to the current storage-node committee. Each storage node signs a receipt for what it accepted, those receipts are aggregated, and the aggregate is submitted back to the Sui blob object to certify the blob. Certification emits a Sui event that includes the blob ID and the period of availability, and Walrus treats certification—not “upload started,” not “upload finished”—as the moment the blob is actually available.
If that sounds a bit bureaucratic, it’s worth sitting with why it exists. In any system where multiple parties rely on the same data—rollups, audit trails, model artifacts, media archives—“we uploaded it” is a weak claim. Walrus makes “this specific content was stored and is promised available through epoch X” something you can point to and verify. The protocol is explicit about how verification works in practice: you can authenticate the certified-blob event, check the blob object state, or even verify from inside a Sui smart contract.
Retrieval mirrors that same posture: verify first, then fetch. A read begins with the blob ID, then the reader queries the Walrus system object on Sui to learn the current storage-node committee for the relevant epoch. With that committee in hand, the client (or an aggregator service) requests metadata and enough slices from a subset of nodes to reconstruct the file, and it checks the reconstruction against the blob ID before returning bytes. Walrus is unusually specific about fault tolerance here: reads are designed to succeed even if up to one third of storage nodes are unavailable, and in many cases, after nodes synchronize, reads can still succeed even if two thirds are down.
In practice, the choice that shapes developer experience most is whether you read and write directly or through services. Walrus supports a CLI, a daemon HTTP mode, and aggregator/publisher services. The TypeScript SDK is candid about what direct interaction entails: writing a blob can require on the order of a couple thousand requests and reading a few hundred, which is why many apps prefer publishers and aggregators—or an upload relay that offloads the fan-out writes to a server. This isn’t a knock; it’s the honest cost of talking to many independent nodes and not pretending a distributed network behaves like one machine.
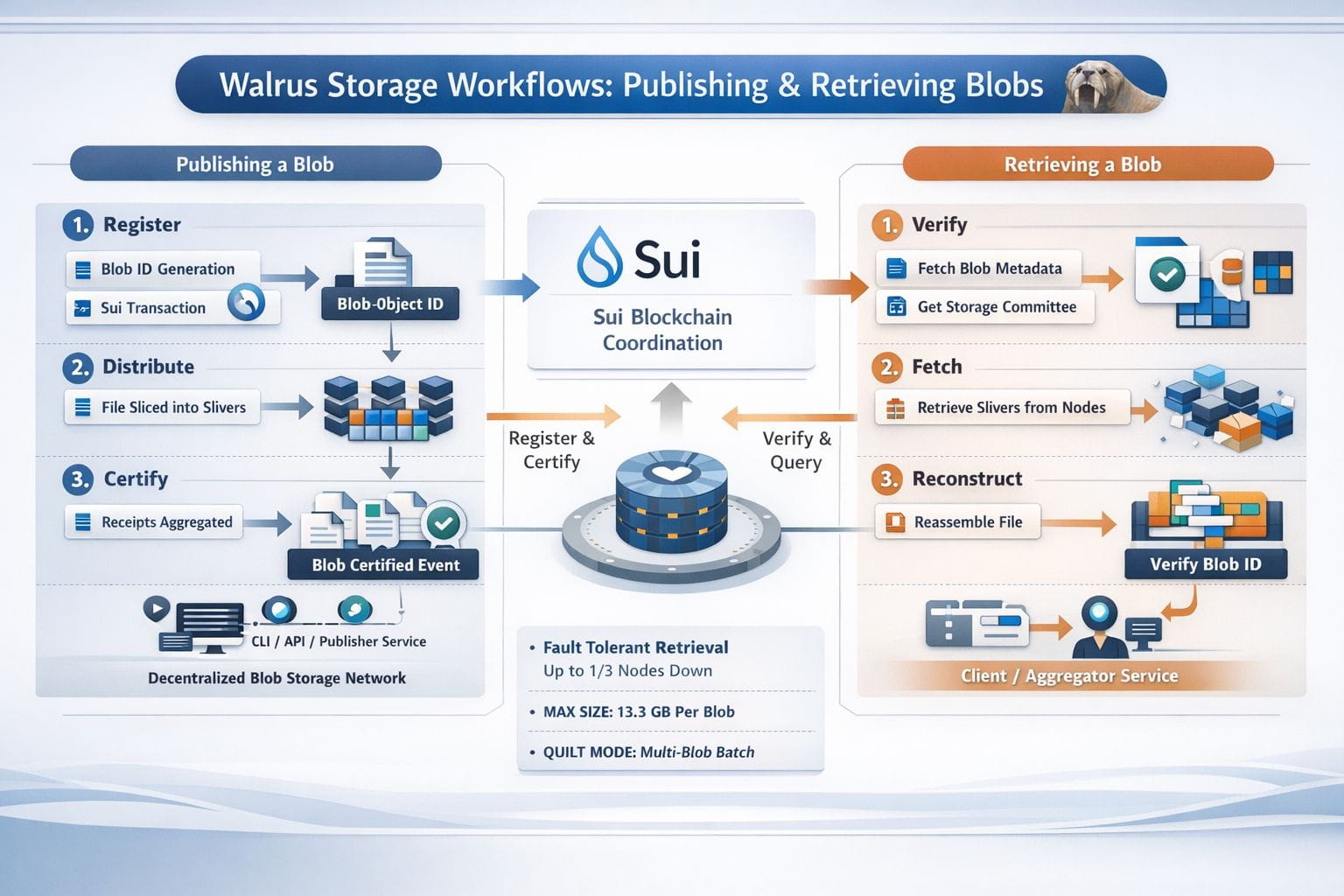
There are also boundaries you can’t ignore. All blobs stored in Walrus are public and discoverable, so confidential data requires encryption before storage. Storage is time-bounded by design: you choose how many epochs to store at publish time, and mainnet epochs are two weeks. The maximum blob size is currently 13.3 GB, which pushes larger datasets toward chunking—or toward quilts, Walrus’s batch format that lets you store multiple blobs together and later retrieve by quilt ID plus an internal identifier.
So why does this feel particularly relevant right now, beyond the general “more data” story? Two reasons. First, the ecosystem has normalized “blobs” as a first-class concept since Dencun, so teams are finally designing around temporary versus durable data instead of mixing everything together. Second, Walrus is starting to get tested by the kind of workloads that make or break storage promises—huge media libraries, for example. In January 2026, the Walrus Foundation highlighted Team Liquid migrating 250TB of match footage and brand content to the protocol, which is exactly the sort of archive where retrieval reliability and content integrity stop being abstract virtues.
Walrus isn’t “Dropbox on a blockchain,” and expecting it to behave that way is a quick route to frustration. But if you look at it as a system built around proof—publish in a way that can be verified, retrieve in a way that can be checked—it starts to make sense. At that point, the title isn’t poetic. It’s literally what you’re doing.