Tác giả: 0xjacobzhao | https://linktr.ee/0xjacobzhao
Báo cáo nghiên cứu độc lập này được hỗ trợ bởi IOSG Ventures. Quá trình nghiên cứu và viết được lấy cảm hứng từ công trình của Sam Lehman (Pantera Capital) về học củng cố. Cảm ơn Ben Fielding (Gensyn.ai), Gao Yuan(Gradient), Samuel Dare & Erfan Miahi (Covenant AI), Shashank Yadav (Fraction AI), Chao Wang vì những gợi ý quý giá của họ cho bài viết này. Bài viết này cố gắng đạt được tính khách quan và chính xác, nhưng một số quan điểm liên quan đến đánh giá chủ quan và có thể chứa đựng sự thiên lệch. Chúng tôi trân trọng sự hiểu biết của độc giả.
Trí tuệ nhân tạo đang chuyển mình từ học tập thống kê dựa trên mẫu sang các hệ thống lý luận có cấu trúc, với đào tạo sau—đặc biệt là học tăng cường—trở thành trung tâm cho việc mở rộng khả năng. DeepSeek-R1 đánh dấu một sự thay đổi trong mô hình: học tăng cường hiện nay cho thấy sự cải thiện rõ rệt về độ sâu lý luận và khả năng ra quyết định phức tạp, phát triển từ một công cụ điều chỉnh đơn thuần thành một con đường nâng cao trí tuệ liên tục.
Song song, Web3 đang định hình sản xuất AI thông qua tính toán phi tập trung và khuyến khích tiền điện tử, mà tính khả thi và phối hợp của chúng phù hợp tự nhiên với nhu cầu của học tăng cường. Báo cáo này xem xét các mô hình đào tạo AI và các nguyên tắc học tăng cường, làm nổi bật những ưu điểm cấu trúc của “Học Tăng cường × Web3,” và phân tích Prime Intellect, Gensyn, Nghiên cứu Nous, Gradient, Grail và Fraction AI.
I. Ba Giai đoạn Đào tạo AI
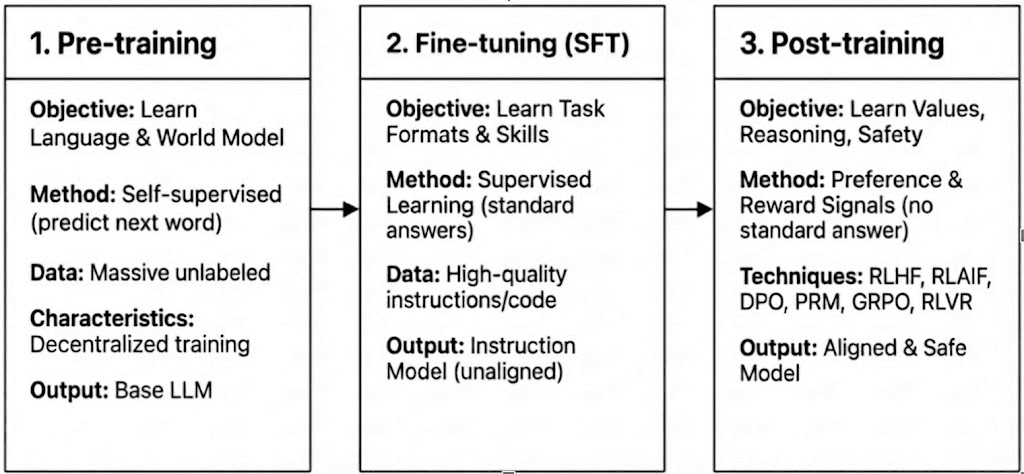
Đào tạo LLM hiện đại trải qua ba giai đoạn—đào tạo trước, tinh chỉnh có giám sát (SFT), và đào tạo sau/ học tăng cường—tương ứng với việc xây dựng một mô hình thế giới, tiêm khả năng nhiệm vụ, và định hình lý luận và giá trị. Các đặc điểm tính toán và xác minh của chúng xác định mức độ tương thích của chúng với phân quyền.
Đào tạo trước: thiết lập các nền tảng thống kê và đa phương thức cốt lõi thông qua việc học tự giám sát quy mô lớn, tiêu thụ 80–95% tổng chi phí và yêu cầu các cụm GPU đồng bộ hóa chặt chẽ, đồng nhất và truy cập dữ liệu băng thông cao, khiến nó vốn dĩ tập trung.
Tinh chỉnh có giám sát (SFT): thêm các khả năng nhiệm vụ và hướng dẫn với các tập dữ liệu nhỏ hơn và chi phí thấp hơn (5–15%), thường sử dụng các phương pháp PEFT như LoRA hoặc Q-LoRA, nhưng vẫn phụ thuộc vào đồng bộ hóa độ dốc, hạn chế sự phân quyền.
Đào tạo sau: Đào tạo sau bao gồm nhiều giai đoạn lặp lại định hình khả năng lý luận, giá trị và ranh giới an toàn của một mô hình. Nó bao gồm cả các phương pháp dựa trên RL (ví dụ: RLHF, RLAIF, GRPO), tối ưu hóa sở thích không phải RL (ví dụ: DPO), và các mô hình phần thưởng quy trình (PRM). Với yêu cầu dữ liệu và chi phí thấp hơn (khoảng 5–10%), tính toán tập trung vào các vòng và cập nhật chính sách. Hỗ trợ tự nhiên của nó cho thực thi phân tán không đồng bộ—thường không yêu cầu trọng số đầy đủ của mô hình—làm cho đào tạo sau là giai đoạn phù hợp nhất cho các mạng đào tạo phân quyền dựa trên Web3 khi kết hợp với tính toán có thể xác minh và khuyến khích trên chuỗi.
II. Cảnh quan Công nghệ Học Tăng cường
2.1 Kiến trúc Hệ thống của Học Tăng cường
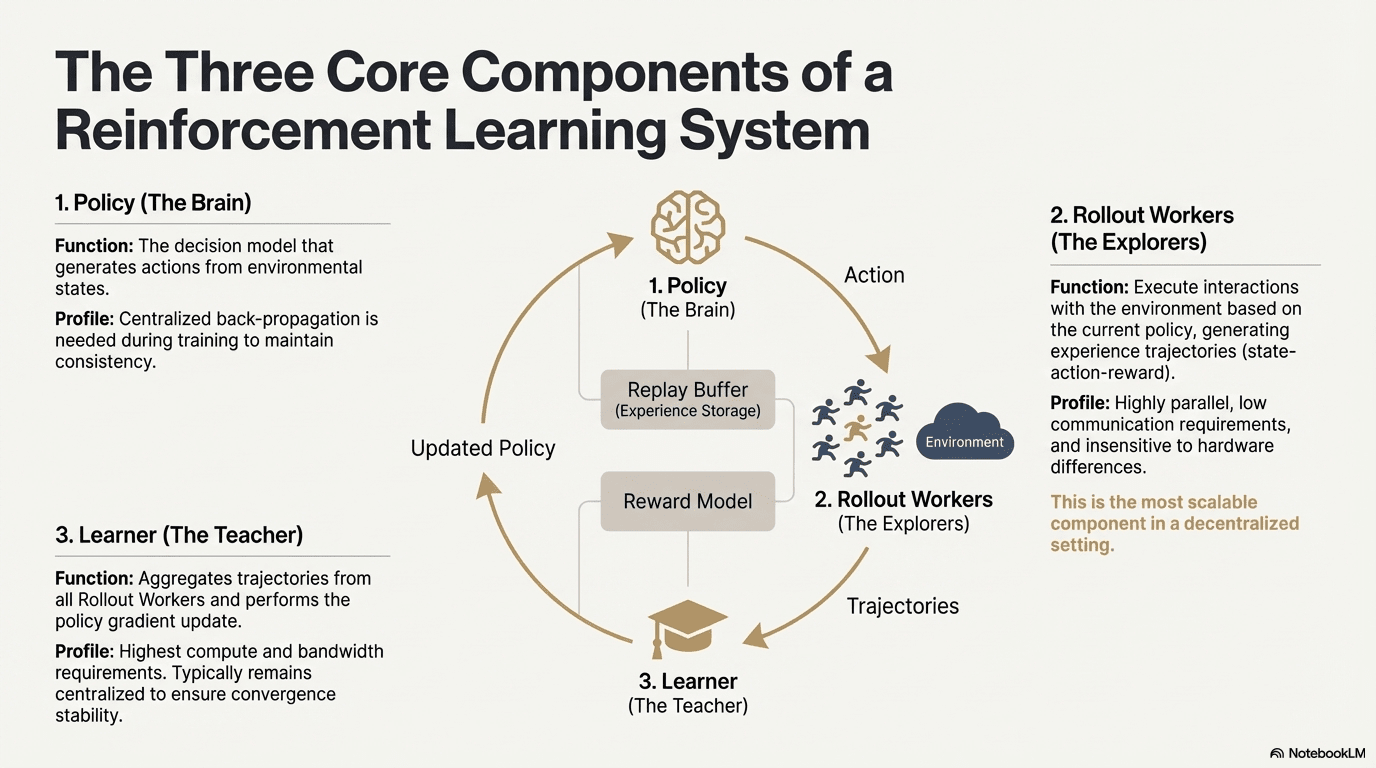
Học tăng cường cho phép các mô hình cải thiện khả năng ra quyết định thông qua vòng phản hồi của tương tác môi trường, tín hiệu phần thưởng và cập nhật chính sách. Cấu trúc, một hệ thống RL bao gồm ba thành phần cốt lõi: mạng chính sách, vòng cho việc lấy mẫu kinh nghiệm và người học cho việc tối ưu hóa chính sách. Chính sách tạo ra các lộ trình thông qua tương tác với môi trường, trong khi người học cập nhật chính sách dựa trên các phần thưởng, hình thành một quá trình học tập lặp đi lặp lại liên tục.
Mạng Chính sách (Chính sách): Tạo ra các hành động từ các trạng thái môi trường và là lõi quyết định của hệ thống. Nó yêu cầu lan truyền ngược tập trung để duy trì tính nhất quán trong quá trình đào tạo; trong quá trình suy diễn, nó có thể được phân phối đến các nút khác nhau để hoạt động song song.
Lấy mẫu Kinh nghiệm (Vòng): Các nút thực hiện tương tác môi trường dựa trên chính sách, tạo ra các lộ trình trạng thái-hành động-phần thưởng. Quy trình này rất song song, có giao tiếp cực thấp, không nhạy cảm với sự khác biệt phần cứng và là thành phần phù hợp nhất để mở rộng trong phân quyền.
Người học: Tập hợp tất cả các lộ trình Vòng và thực hiện cập nhật độ dốc chính sách. Đây là mô-đun duy nhất có yêu cầu cao nhất về sức mạnh tính toán và băng thông, vì vậy nó thường được giữ trung tâm hoặc nhẹ nhàng trung tâm để đảm bảo ổn định hội tụ.
2.2 Khung Giai đoạn Học Tăng cường
Học tăng cường thường có thể được chia thành năm giai đoạn, và quy trình tổng thể như sau:
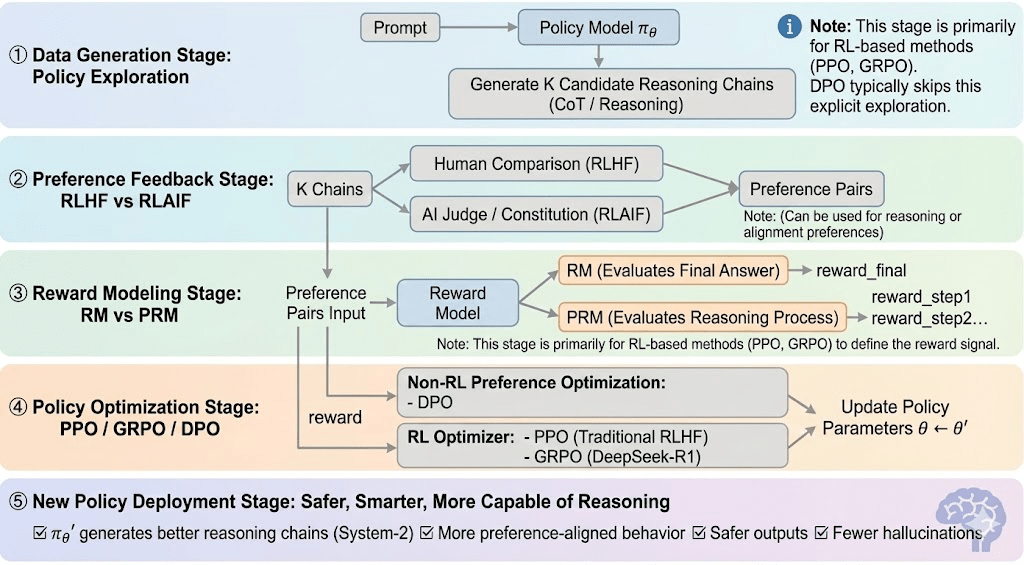
Giai đoạn Tạo Dữ liệu (Khám phá Chính sách): Được đưa ra một nhắc nhở, chính sách lấy mẫu nhiều chuỗi lý luận hoặc lộ trình, cung cấp các ứng viên cho việc đánh giá sở thích và mô hình phần thưởng, và xác định phạm vi khám phá chính sách.
Giai đoạn Phản hồi Sở thích (RLHF / RLAIF):
RLHF (Học Tăng cường từ Phản hồi của Con người): đào tạo một mô hình phần thưởng từ sở thích của con người và sau đó sử dụng RL (thường là PPO) để tối ưu hóa chính sách dựa trên tín hiệu phần thưởng đó.
RLAIF (Học Tăng cường từ Phản hồi của AI): thay thế con người bằng các thẩm phán AI hoặc quy tắc hiến pháp, cắt giảm chi phí và mở rộng sự điều chỉnh—nay là phương pháp chiếm ưu thế cho Anthropic, OpenAI và DeepSeek.
Giai đoạn Mô hình Phần thưởng (Mô hình Phần thưởng): Học cách ánh xạ đầu ra với phần thưởng dựa trên các cặp sở thích. RM dạy mô hình "câu trả lời đúng là gì," trong khi PRM dạy mô hình "cách lý luận đúng."
RM (Mô hình Phần thưởng): Được sử dụng để đánh giá chất lượng của câu trả lời cuối cùng, chỉ chấm điểm đầu ra.
Mô hình Phần thưởng Quy trình (PRM): chấm điểm lý luận từng bước, hiệu quả đào tạo quy trình lý luận của mô hình (ví dụ: trong o1 và DeepSeek-R1).
Xác minh Phần thưởng (RLVR / Khả năng Xác minh Phần thưởng): Một lớp xác minh phần thưởng giới hạn tín hiệu phần thưởng phải được rút ra từ các quy tắc có thể tái tạo, các sự thật cơ bản, hoặc các cơ chế đồng thuận. Điều này giảm thiểu gian lận phần thưởng và thiên lệch hệ thống, và cải thiện khả năng kiểm toán và độ tin cậy trong các môi trường đào tạo mở và phân phối.
Giai đoạn Tối ưu hóa Chính sách (Tối ưu hóa Chính sách): Cập nhật các tham số chính sách $\theta$ dưới sự hướng dẫn của các tín hiệu do mô hình phần thưởng cung cấp để có được một chính sách $\pi_{\theta'}$ với khả năng lý luận mạnh mẽ hơn, an toàn hơn và các mẫu hành vi ổn định hơn. Các phương pháp tối ưu hóa chính thống bao gồm:
PPO (Tối ưu hóa Chính sách Gần): bộ tối ưu hóa RLHF tiêu chuẩn, được đánh giá cao vì tính ổn định nhưng bị hạn chế bởi sự hội tụ chậm trong lý luận phức tạp.
GRPO (Tối ưu hóa Chính sách Tương đối Nhóm): được giới thiệu bởi DeepSeek-R1, tối ưu hóa các chính sách sử dụng ước tính lợi thế cấp nhóm thay vì xếp hạng đơn giản, bảo tồn độ lớn giá trị và cho phép tối ưu hóa chuỗi lý luận ổn định hơn.
DPO (Tối ưu hóa Sở thích Trực tiếp): vượt qua RL bằng cách tối ưu hóa trực tiếp trên các cặp sở thích—rẻ và ổn định cho việc điều chỉnh, nhưng không hiệu quả trong việc cải thiện lý luận.
Giai đoạn Triển khai Chính sách Mới (Triển khai Chính sách Mới): mô hình đã được cập nhật cho thấy khả năng lý luận Hệ thống-2 mạnh mẽ hơn, sự điều chỉnh sở thích tốt hơn, ít ảo tưởng hơn và an toàn hơn, và tiếp tục cải thiện thông qua các vòng phản hồi lặp đi lặp lại.

2.3 Ứng dụng Công nghiệp của Học Tăng cường
Học Tăng cường (RL) đã phát triển từ trí tuệ trò chơi ban đầu thành một khung cốt lõi cho việc ra quyết định tự động xuyên ngành. Các kịch bản ứng dụng của nó, dựa trên sự trưởng thành công nghệ và triển khai công nghiệp, có thể được tóm tắt thành năm loại chính:
Trò chơi & Chiến lược: Hướng đi sớm nhất mà RL đã được xác minh. Trong các môi trường "thông tin hoàn hảo + phần thưởng rõ ràng" như AlphaGo, AlphaZero, AlphaStar, và OpenAI Five, RL đã chứng minh trí thông minh quyết định tương đương hoặc vượt trội hơn các chuyên gia con người, đặt nền tảng cho các thuật toán RL hiện đại.
Robot và AI Nhúng: Thông qua kiểm soát liên tục, mô hình động lực và tương tác môi trường, RL cho phép robot học thao tác, điều khiển chuyển động và các nhiệm vụ đa mô thức (ví dụ: RT-2, RT-X). Nó đang nhanh chóng tiến tới công nghiệp hóa và là một con đường kỹ thuật chính cho việc triển khai robot trong thế giới thực.
Lý luận Kỹ thuật số / Hệ thống LLM-2: RL + PRM thúc đẩy các mô hình lớn từ "bắt chước ngôn ngữ" đến "lý luận có cấu trúc." Những thành tựu tiêu biểu bao gồm DeepSeek-R1, OpenAI o1/o3, Anthropic Claude, và AlphaGeometry. Về cơ bản, nó thực hiện tối ưu hóa phần thưởng ở cấp độ chuỗi lý luận thay vì chỉ đánh giá câu trả lời cuối cùng.
Khám Phá Khoa Học & Tối ưu hóa Toán Học: RL tìm ra các cấu trúc hoặc chiến lược tối ưu trong không có nhãn, phần thưởng phức tạp và không gian tìm kiếm lớn. Nó đã đạt được các bước đột phá nền tảng trong AlphaTensor, AlphaDev, và Fusion RL, cho thấy khả năng khám phá vượt xa trí tuệ con người.
Ra quyết định Kinh tế & Giao dịch: RL được sử dụng để tối ưu hóa chiến lược, kiểm soát rủi ro đa chiều và tạo ra hệ thống giao dịch thích ứng. So với các mô hình định lượng truyền thống, nó có thể học liên tục trong các môi trường không chắc chắn và là một thành phần quan trọng của tài chính thông minh.
III. Sự Khớp Tự Nhiên Giữa Học Tăng cường và Web3
Học tăng cường và Web3 tự nhiên khớp nhau như các hệ thống dựa trên khuyến khích: RL tối ưu hóa hành vi thông qua phần thưởng, trong khi các blockchain phối hợp người tham gia thông qua các khuyến khích kinh tế. Các nhu cầu cốt lõi của RL—các vòng dị dạng quy mô lớn, phân phối phần thưởng và thực thi có thể xác minh—tương ứng trực tiếp với những điểm mạnh cấu trúc của Web3.
Tách rời Lý luận và Đào tạo: Học tăng cường tách thành các giai đoạn vòng và cập nhật: các vòng là nặng tính toán nhưng nhẹ giao tiếp và có thể chạy song song trên các GPU tiêu dùng phân tán, trong khi các cập nhật yêu cầu tài nguyên tập trung với băng thông cao. Việc tách biệt này cho phép các mạng mở xử lý các vòng với khuyến khích token, trong khi các cập nhật tập trung duy trì ổn định đào tạo.
Khả năng xác minh: ZK (Không Biết) và Bằng chứng Học tập cung cấp các phương tiện để xác minh xem các nút có thực sự thực hiện lý luận hay không, giải quyết vấn đề độ trung thực trong các mạng mở. Trong các nhiệm vụ xác định như mã và lý luận toán học, người xác minh chỉ cần kiểm tra câu trả lời để xác nhận khối lượng công việc, cải thiện đáng kể độ tin cậy của các hệ thống RL phân phối.
Tầng Khuyến khích, Cơ chế Sản xuất Phản hồi Dựa trên Kinh tế Token: Các khuyến khích token Web3 có thể trực tiếp thưởng cho các người đóng góp phản hồi RLHF/RLAIF, cho phép tạo ra sở thích minh bạch, không cần quyền, với staking và slashing thực thi chất lượng hiệu quả hơn so với các phương pháp crowdsourcing truyền thống.
Tiềm năng cho Học Tăng cường Đa tác nhân (MARL): Các blockchain tạo ra các môi trường đa tác nhân mở, dựa trên khuyến khích với trạng thái công khai, thực thi có thể xác minh và khuyến khích có thể lập trình, khiến chúng trở thành một bệ thử nghiệm tự nhiên cho MARL quy mô lớn mặc dù lĩnh vực này vẫn còn sớm.
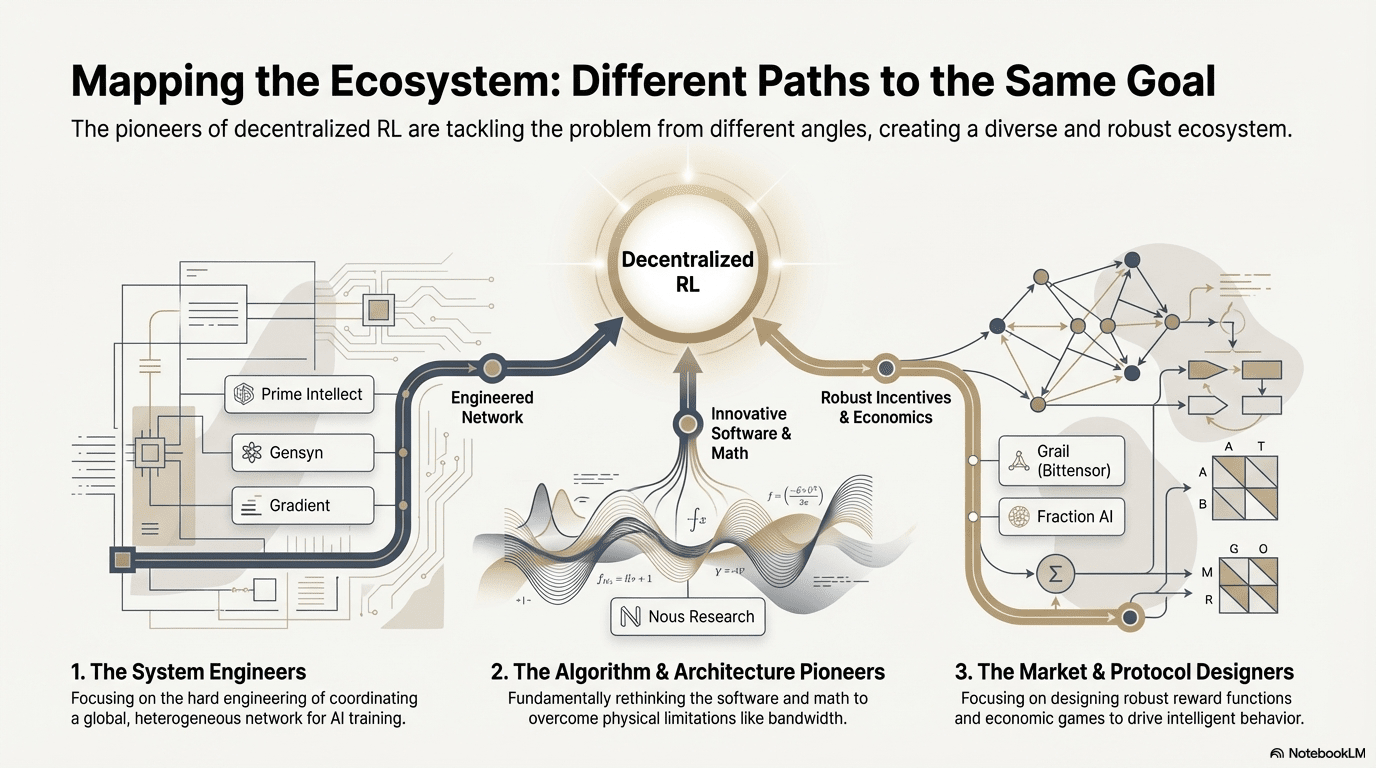
IV. Phân tích các Dự án Web3 + Học Tăng cường
Dựa trên khung lý thuyết trên, chúng tôi sẽ phân tích ngắn gọn các dự án đại diện nhất trong hệ sinh thái hiện tại:
Prime Intellect: Học Tăng cường không đồng bộ prime-rl
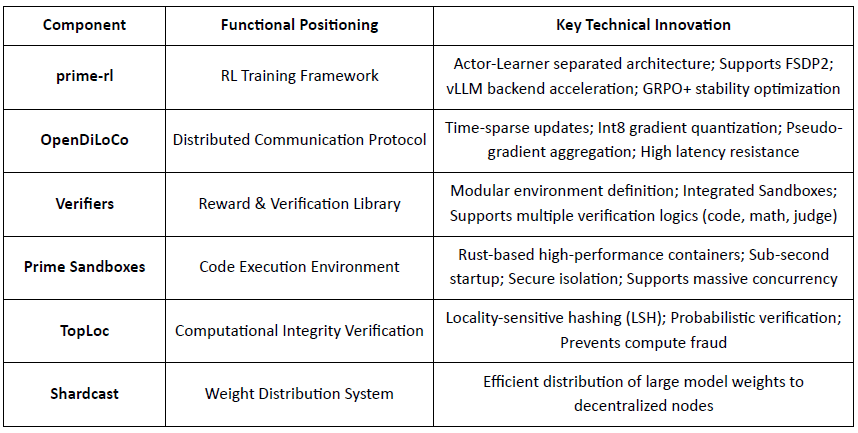
Prime Intellect nhằm mục đích xây dựng một thị trường tính toán toàn cầu mở và ngăn xếp siêu trí tuệ mã nguồn mở, trải dài từ Prime Compute, gia đình mô hình INTELLECT, các môi trường RL mã nguồn mở, và các động cơ dữ liệu tổng hợp quy mô lớn. Khung prime-rl cốt lõi của nó được thiết kế đặc biệt cho RL phân tán không đồng bộ, được bổ sung bởi OpenDiLoCo cho đào tạo tiết kiệm băng thông và TopLoc cho việc xác minh.
Tổng quan về Các Thành phần Hạ tầng Cốt lõi của Prime Intellect
Nền tảng Kỹ thuật: prime-rl Khung Học Tăng cường Không đồng bộ
prime-rl là động cơ đào tạo cốt lõi của Prime Intellect, được thiết kế cho các môi trường phân tán không đồng bộ quy mô lớn. Nó đạt được suy diễn có thông lượng cao và cập nhật ổn định thông qua việc tách rời hoàn toàn Actor–Learner. Các Người thực thi (Công nhân Vòng) và Người học (Huấn luyện viên) không chặn đồng bộ. Các nút có thể tham gia hoặc rời khỏi bất kỳ lúc nào, chỉ cần liên tục kéo chính sách mới nhất và tải lên dữ liệu được tạo ra:
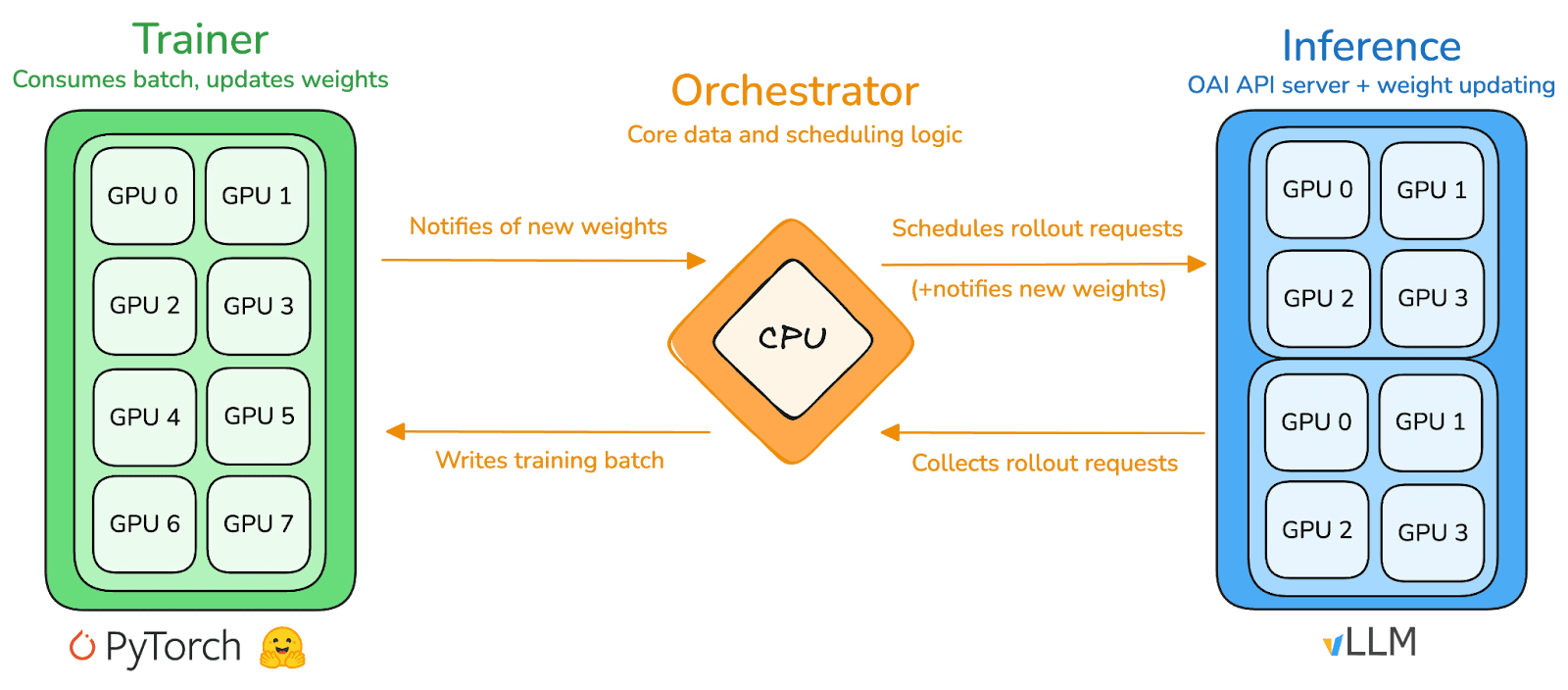
Người diễn xuất (Công nhân Vòng): Chịu trách nhiệm cho suy diễn mô hình và tạo dữ liệu. Prime Intellect đã tích hợp sáng tạo động cơ suy diễn vLLM tại đầu Người diễn xuất. Công nghệ PagedAttention của vLLM và khả năng Batching Liên tục cho phép Người diễn xuất tạo ra các lộ trình suy diễn với thông lượng cực cao.
Người học (Huấn luyện viên): Chịu trách nhiệm cho việc tối ưu hóa chính sách. Người học không đồng bộ kéo dữ liệu từ bộ đệm Kinh nghiệm chung để cập nhật độ dốc mà không cần chờ tất cả các Người diễn xuất hoàn thành lô hiện tại.
Người điều phối: Chịu trách nhiệm cho việc lập lịch các trọng số mô hình và luồng dữ liệu.
Các Đổi mới Chìa khóa của prime-rl:
Tính Không đồng bộ Thực sự: prime-rl từ bỏ mô hình đồng bộ truyền thống của PPO, không chờ các nút chậm, và không yêu cầu căn chỉnh lô, cho phép bất kỳ số lượng và hiệu suất GPU nào truy cập vào bất kỳ lúc nào, thiết lập tính khả thi của RL phân tán.
Tích hợp Sâu giữa FSDP2 và MoE: Thông qua việc phân chia tham số FSDP2 và kích hoạt thưa thớt MoE, prime-rl cho phép các mô hình hàng chục tỷ tham số được đào tạo hiệu quả trong các môi trường phân tán. Các Người diễn xuất chỉ chạy các chuyên gia hoạt động, giảm thiểu đáng kể chi phí VRAM và suy diễn.
GRPO+ (Tối ưu hóa Chính sách Tương đối Nhóm): GRPO loại bỏ mạng Critic, giảm thiểu đáng kể chi phí tính toán và VRAM, tự nhiên thích ứng với các môi trường không đồng bộ. GRPO+ của prime-rl đảm bảo hội tụ đáng tin cậy dưới các điều kiện độ trễ cao thông qua các cơ chế ổn định.
Gia đình Mô hình INTELLECT: Một Biểu tượng của Trưởng thành Công nghệ RL Phân quyền
INTELLECT-1 (10B, Tháng 10 2024): Đã chứng minh lần đầu tiên rằng OpenDiLoCo có thể đào tạo hiệu quả trong một mạng dị dạng trên ba châu lục (chia sẻ giao tiếp < 2%, sử dụng tính toán 98%), phá vỡ các nhận thức vật lý về đào tạo giữa các khu vực.
INTELLECT-2 (32B, Tháng 4 2025): Là mô hình RL đầu tiên không cần quyền, xác thực khả năng hội tụ ổn định của prime-rl và GRPO+ trong các môi trường độ trễ nhiều bước và không đồng bộ, hiện thực hóa RL phân tán với sự tham gia tính toán mở toàn cầu.
INTELLECT-3 (106B MoE, Tháng 11 2025): Áp dụng kiến trúc thưa thớt chỉ kích hoạt 12B tham số, được đào tạo trên 512×H200 và đạt hiệu suất suy diễn hàng đầu (AIME 90.8%, GPQA 74.4%, MMLU-Pro 81.9%, v.v.). Hiệu suất tổng thể gần như hoặc vượt qua các mô hình nguồn đóng lớn hơn nhiều so với nó.
Prime Intellect đã xây dựng một ngăn xếp RL phân quyền đầy đủ: OpenDiLoCo giảm băng thông đào tạo giữa các khu vực xuống mức độ lớn trong khi duy trì ~98% sử dụng trên toàn cầu; TopLoc và các Người xác minh đảm bảo suy diễn và dữ liệu phần thưởng đáng tin cậy thông qua các dấu vân tay kích hoạt và xác minh trong hộp cát; và động cơ dữ liệu SYNTHETIC tạo ra các chuỗi lý luận chất lượng cao trong khi cho phép các mô hình lớn chạy hiệu quả trên các GPU tiêu dùng thông qua song song hóa pipeline. Cùng nhau, các thành phần này hỗ trợ việc tạo dữ liệu, xác minh và suy diễn có thể mở rộng trong RL phân quyền, với chuỗi INTELLECT cho thấy rằng các hệ thống như vậy có thể cung cấp các mô hình đẳng cấp thế giới trong thực tế.
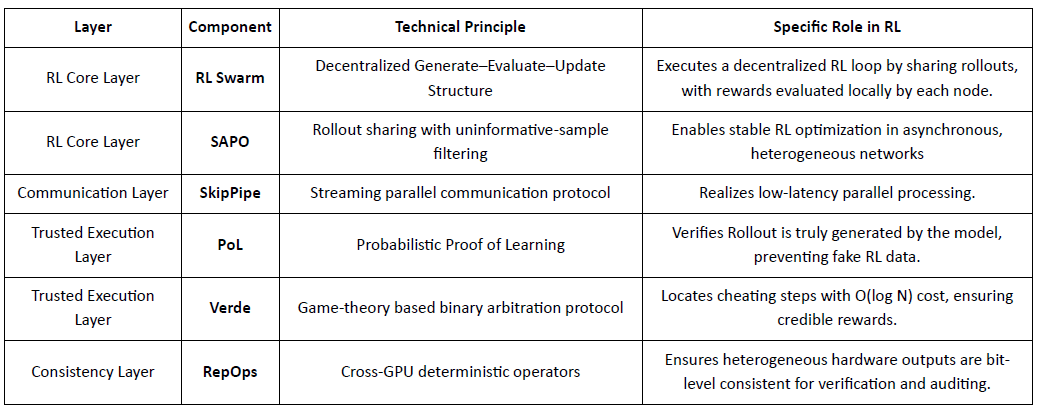
Gensyn: Khung cốt lõi RL RL Swarm và SAPO
Gensyn tìm cách thống nhất sức mạnh tính toán nhàn rỗi toàn cầu thành một mạng đào tạo AI có thể mở rộng, không cần tin cậy, kết hợp thực thi chuẩn hóa, phối hợp P2P và xác minh nhiệm vụ trên chuỗi. Thông qua các cơ chế như RL Swarm, SAPO và SkipPipe, nó tách rời việc tạo ra, đánh giá và cập nhật trên các GPU dị dạng, cung cấp không chỉ tính toán, mà còn trí tuệ có thể xác minh.
Ứng dụng RL trong Đống Gensyn
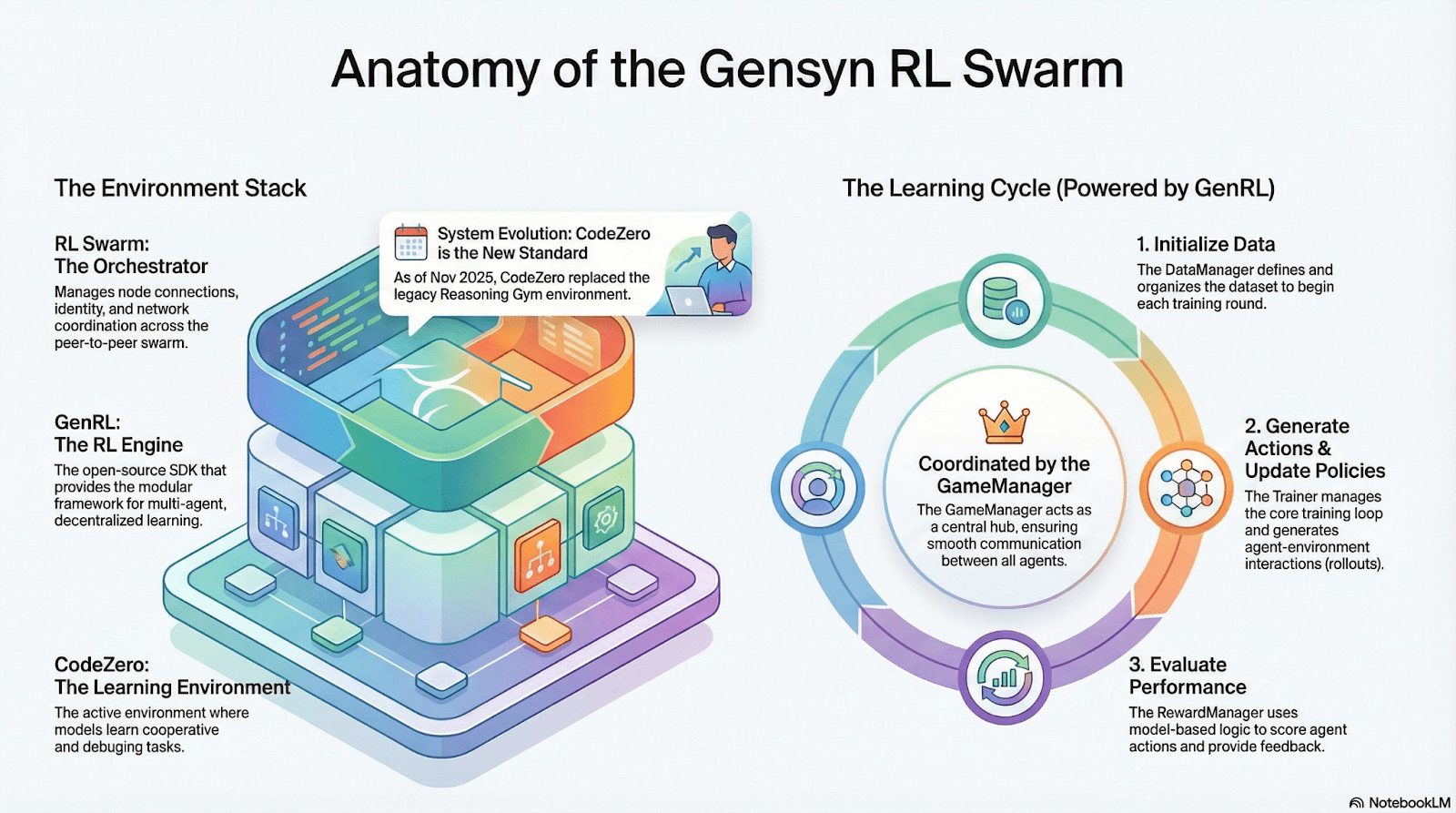
RL Swarm: Động cơ Học Tăng cường Hợp tác Phân tán
RL Swarm chứng minh một chế độ hợp tác hoàn toàn mới. Nó không chỉ đơn giản là phân phối nhiệm vụ, mà là một vòng lặp vô tận của một vòng lặp tạo–đánh giá–cập nhật phân tán được lấy cảm hứng từ việc học hợp tác mô phỏng học tập xã hội con người:
Giải pháp (Người thực thi): Chịu trách nhiệm cho suy diễn mô hình địa phương và tạo ra Vòng, không bị cản trở bởi sự dị dạng của các nút. Gensyn tích hợp các động cơ suy diễn có thông lượng cao (như CodeZero) tại địa phương để đầu ra các lộ trình hoàn chỉnh thay vì chỉ câu trả lời.
Người đề xuất: Tạo ra các nhiệm vụ một cách động (vấn đề toán học, câu hỏi mã, v.v.), cho phép sự đa dạng nhiệm vụ và thích ứng giống như chương trình giảng dạy để điều chỉnh độ khó đào tạo cho phù hợp với khả năng của mô hình.
Người đánh giá: Sử dụng các "Mô hình Thẩm phán" đông lạnh hoặc quy tắc để kiểm tra chất lượng đầu ra, hình thành các tín hiệu phần thưởng địa phương được đánh giá độc lập bởi mỗi nút. Quy trình đánh giá có thể được kiểm toán, giảm bớt không gian cho sự xấu xa.
Ba thành phần tạo thành một cấu trúc tổ chức RL P2P có thể hoàn thành việc học hợp tác quy mô lớn mà không cần lập lịch tập trung.
SAPO: Thuật toán Tối ưu hóa Chính sách Được Tái cấu trúc cho Phân quyền
SAPO (Tối ưu hóa Chính sách Lấy mẫu Đàn) tập trung vào việc chia sẻ các vòng trong khi lọc những vòng không có tín hiệu độ dốc, thay vì chia sẻ độ dốc. Bằng cách cho phép lấy mẫu vòng phân tán quy mô lớn và coi các vòng nhận được là được tạo ra tại địa phương, SAPO duy trì sự hội tụ ổn định trong các môi trường không có phối hợp trung tâm và với sự khác biệt độ trễ nút đáng kể. So với PPO (phụ thuộc vào một mạng critic chiếm ưu thế về chi phí tính toán) hoặc GRPO (phụ thuộc vào ước tính lợi thế cấp nhóm thay vì xếp hạng đơn giản), SAPO cho phép GPU tiêu dùng tham gia hiệu quả vào việc tối ưu hóa RL quy mô lớn với yêu cầu băng thông cực thấp.
Thông qua RL Swarm và SAPO, Gensyn chứng minh rằng học tăng cường—đặc biệt là RLVR sau đào tạo—phù hợp tự nhiên với các kiến trúc phân tán, vì nó phụ thuộc nhiều hơn vào việc khám phá đa dạng thông qua các vòng hơn là đồng bộ hóa tham số tần suất cao. Kết hợp với các hệ thống xác minh PoL và Verde, Gensyn cung cấp một con đường thay thế cho việc đào tạo các mô hình hàng nghìn tỷ tham số: một mạng siêu trí tuệ tự phát triển bao gồm hàng triệu GPU dị dạng trên toàn thế giới.
Nghiên cứu Nous: Môi trường Học Tăng cường Atropos
Nghiên cứu Nous đang xây dựng một ngăn xếp nhận thức tự tiến hóa phân quyền, nơi các thành phần như Hermes, Atropos, DisTrO, Psyche và World Sim hình thành một hệ thống trí tuệ kín. Sử dụng các phương pháp RL như DPO, GRPO và lấy mẫu từ chối, nó thay thế các đường ống đào tạo tuyến tính bằng phản hồi liên tục giữa việc tạo dữ liệu, học tập và suy diễn.
Tổng quan về Các Thành phần Nghiên cứu Nous
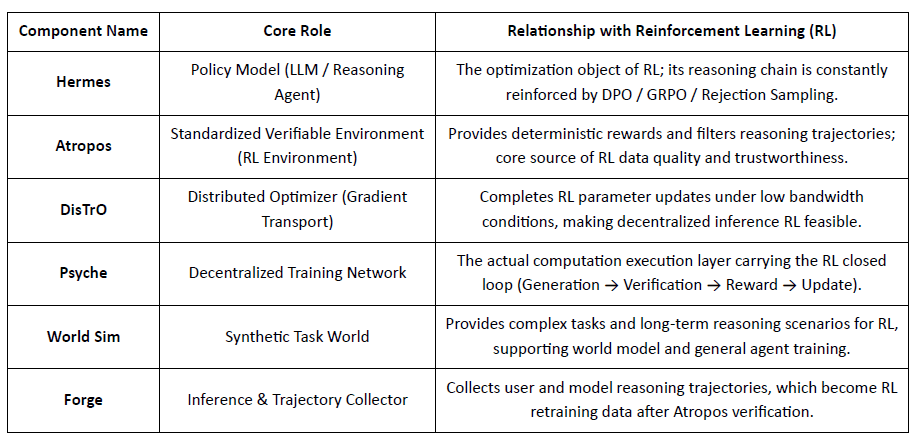
Tầng Mô hình: Hermes và Sự Tiến hóa của Các Khả năng Lý luận
Chuỗi Hermes là giao diện mô hình chính của Nghiên cứu Nous đối diện với người dùng. Sự tiến hóa của nó rõ ràng thể hiện con đường công nghiệp chuyển từ điều chỉnh SFT/DPO truyền thống sang Lý luận RL:
Hermes 1–3: Điều Chỉnh Hướng dẫn & Các Khả Năng Đại Lý Sớm: Hermes 1–3 dựa vào DPO chi phí thấp cho điều chỉnh hướng dẫn mạnh mẽ và tận dụng dữ liệu tổng hợp và sự giới thiệu đầu tiên của các cơ chế xác minh Atropos trong Hermes 3.
Hermes 4 / DeepHermes: Viết kiểu suy nghĩ chậm của Hệ thống-2 vào trọng số thông qua Chuỗi Lý luận, cải thiện hiệu suất toán học và mã với Quy mô Thời gian Kiểm tra, và dựa vào "Lấy mẫu Từ chối + Xác minh Atropos" để xây dựng dữ liệu lý luận có độ tinh khiết cao.
DeepHermes tiếp tục áp dụng GRPO để thay thế PPO (cái mà khó triển khai chủ yếu), cho phép Lý luận RL hoạt động trên mạng GPU phân quyền Psyche, đặt nền tảng kỹ thuật cho khả năng mở rộng của lý luận RL mã nguồn mở.
Atropos: Môi trường Học Tăng cường Dựa trên Phần thưởng Có thể xác minh
Atropos là trung tâm thực sự của hệ thống RL Nous. Nó bao gồm các nhắc nhở, gọi công cụ, thực thi mã và tương tác nhiều lượt vào một môi trường RL chuẩn hóa, xác minh trực tiếp xem đầu ra có chính xác hay không, do đó cung cấp tín hiệu phần thưởng xác định để thay thế việc gán nhãn người dùng tốn kém và không thể mở rộng. Quan trọng hơn, trong mạng lưới đào tạo phi tập trung Psyche, Atropos đóng vai trò như một "quan tòa" để xác minh xem các nút có thực sự cải thiện chính sách hay không, hỗ trợ bằng chứng có thể kiểm toán của Học Tập, giải quyết cơ bản vấn đề độ tin cậy của phần thưởng trong RL phân phối.
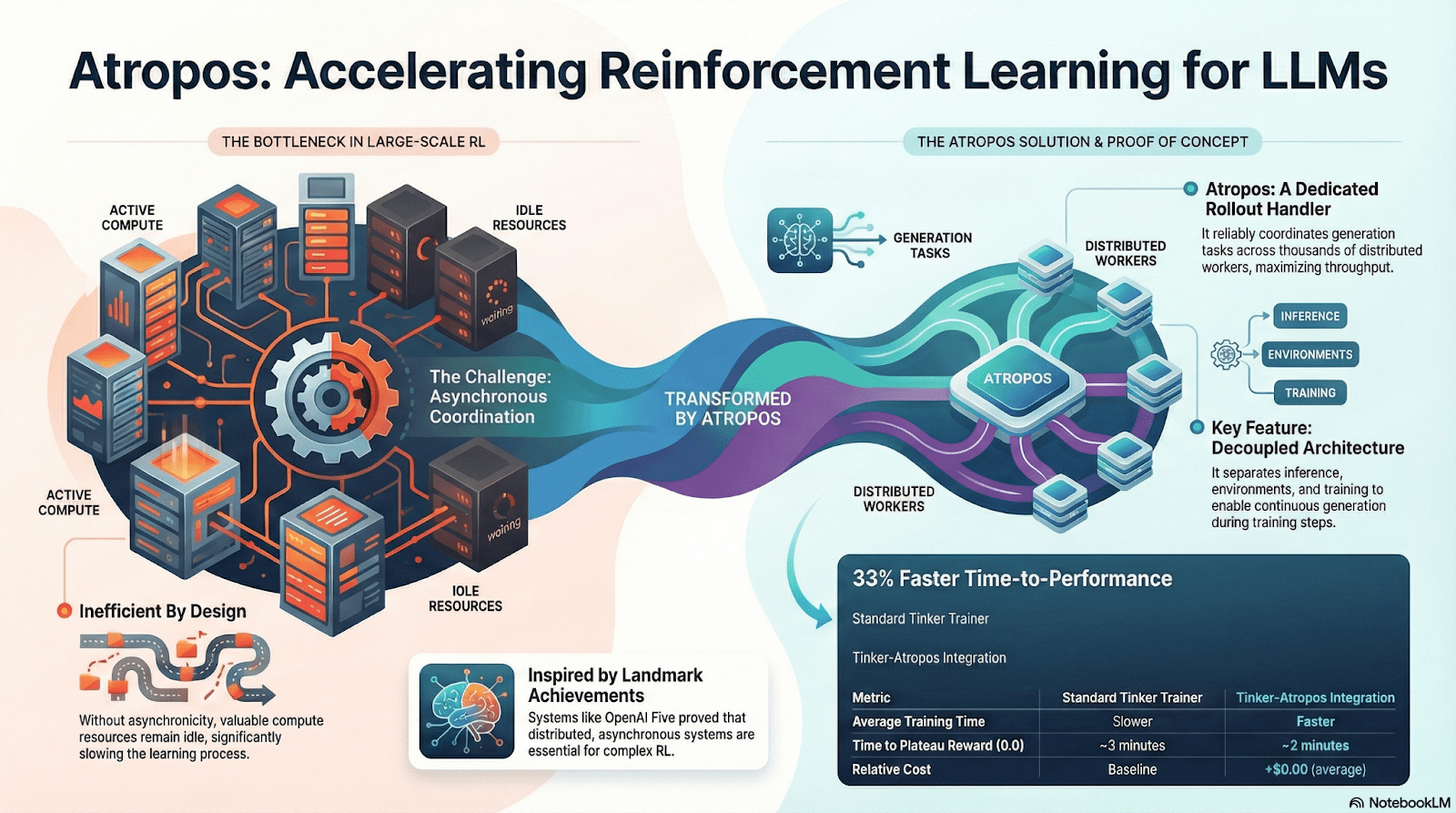
DisTrO và Psyche: Tầng Tối ưu hóa cho Học Tăng cường Phân tán
Đào tạo RLF truyền thống (RLHF/RLAIF) phụ thuộc vào các cụm băng thông cao tập trung, một rào cản cốt lõi mà mã nguồn mở không thể tái tạo. DisTrO giảm chi phí giao tiếp RL xuống mức độ lớn thông qua phân tách động lực và nén độ dốc, cho phép đào tạo chạy trên băng thông internet; Psyche triển khai cơ chế đào tạo này trên một mạng chuỗi, cho phép các nút hoàn thành suy diễn, xác minh, đánh giá phần thưởng, và cập nhật trọng số tại địa phương, hình thành một vòng kín RL hoàn chỉnh.
Trong hệ thống Nous, Atropos xác minh các chuỗi suy nghĩ; DisTrO nén giao tiếp đào tạo; Psyche chạy vòng RL; World Sim cung cấp các môi trường phức tạp; Forge thu thập lý luận thực tế; Hermes ghi lại tất cả việc học vào trọng số. Học tăng cường không chỉ là một giai đoạn đào tạo, mà là giao thức cốt lõi kết nối dữ liệu, môi trường, mô hình và cơ sở hạ tầng trong kiến trúc Nous, khiến Hermes trở thành một hệ thống sống có khả năng tự cải thiện liên tục trên một mạng tính toán mở.
Mạng Gradient: Kiến trúc Học Tăng cường
Mạng Gradient nhằm xây dựng tính toán AI qua một Ngăn xếp Trí tuệ Mở: một tập hợp mô-đun của các giao thức tương tác có thể thay thế trải rộng trên giao tiếp P2P (Lattica), suy diễn phân tán (Parallax), đào tạo RL phi tập trung (Echo), xác minh (VeriLLM), mô phỏng (Mirage), và việc điều phối bộ nhớ và tác nhân cấp cao hơn—kết hợp cùng nhau tạo thành một cơ sở hạ tầng trí tuệ phân tán đang phát triển.
Echo — Kiến trúc Đào tạo Học Tăng cường
Echo là framework học tăng cường của Gradient. Nguyên tắc thiết kế cốt lõi của nó nằm ở việc tách biệt đào tạo, suy diễn và các con đường dữ liệu (phần thưởng) trong học tăng cường, chạy chúng riêng biệt trong Inference Swarm và Training Swarm dị dạng, duy trì hành vi tối ưu ổn định trên các môi trường dị dạng rộng lớn với các giao thức đồng bộ hóa nhẹ. Điều này hiệu quả giảm thiểu các thất bại SPMD và nút thắt trong việc sử dụng GPU do việc trộn lẫn suy diễn và đào tạo trong học tăng cường / VERL truyền thống.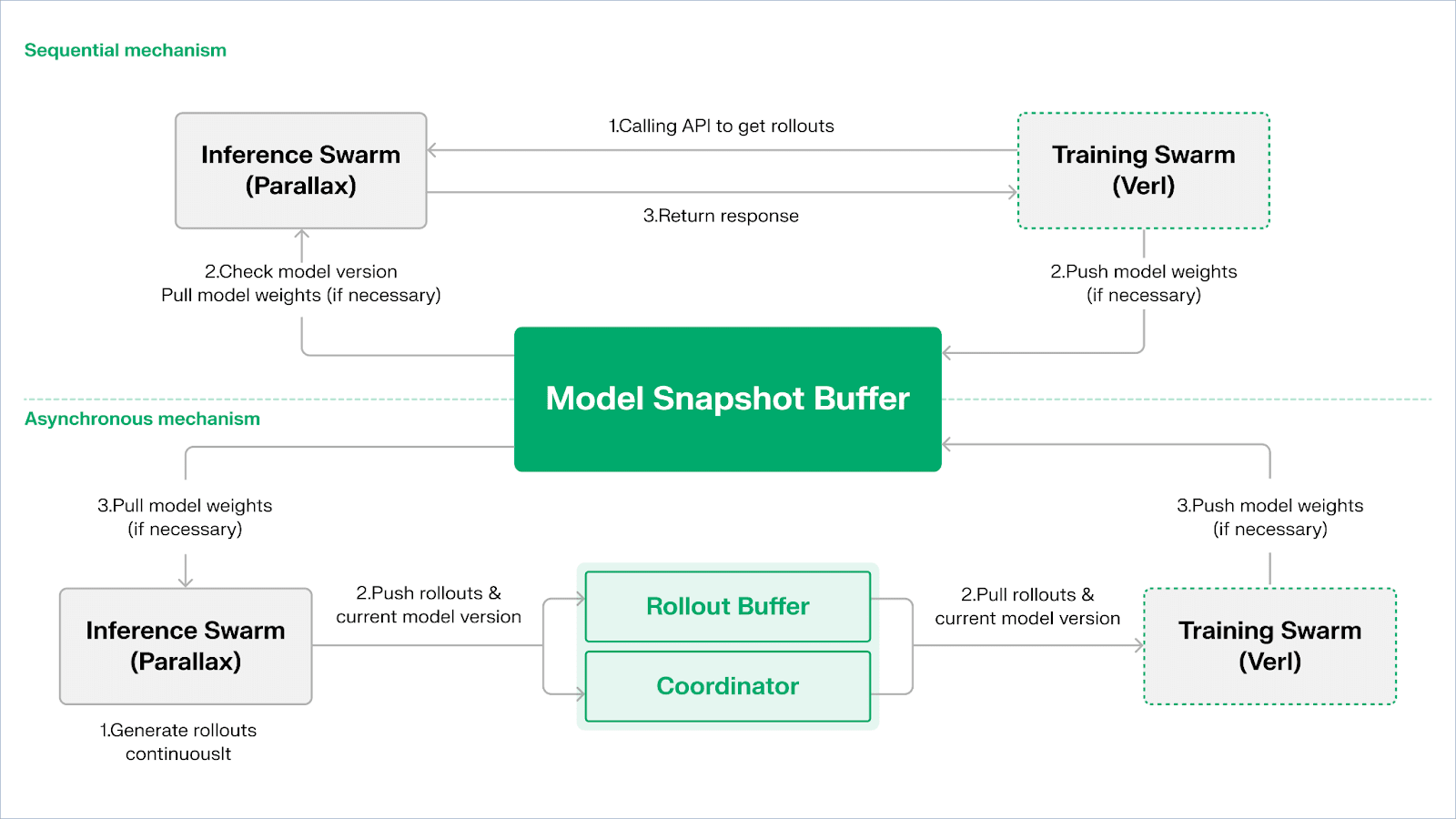
Echo sử dụng "Kiến trúc Đàn Đôi Suy diễn-Đào tạo" để tối đa hóa việc sử dụng sức mạnh tính toán. Hai đàn chạy độc lập mà không chặn lẫn nhau:
Tối đa hóa Thông lượng Lấy mẫu: Inference Swarm bao gồm các GPU tiêu dùng và thiết bị biên, xây dựng các bộ lấy mẫu có thông lượng cao thông qua pipeline-parallel với Parallax, tập trung vào việc tạo ra các lộ trình.
Tối đa hóa Sức mạnh Tính toán Độ dốc: Training Swarm có thể chạy trên các cụm tập trung hoặc mạng GPU tiêu dùng phân tán toàn cầu, chịu trách nhiệm cho các cập nhật độ dốc, đồng bộ hóa tham số và tinh chỉnh LoRA, tập trung vào quá trình học.
Để duy trì tính nhất quán của chính sách và dữ liệu, Echo cung cấp hai loại giao thức đồng bộ hóa nhẹ: Tuần tự và Không đồng bộ, quản lý tính nhất quán hai chiều của trọng số chính sách và các lộ trình:
Chế độ Kéo Tuần tự (Độ chính xác Trước): Bên đào tạo buộc các nút suy diễn phải làm mới phiên bản mô hình trước khi kéo các lộ trình mới để đảm bảo sự tươi mới của lộ trình, phù hợp với các nhiệm vụ cực nhạy cảm với độ cũ của chính sách.
Chế độ Đẩy-Kéo Không đồng bộ (Hiệu quả Trước): Bên suy diễn liên tục tạo ra các lộ trình với các thẻ phiên bản, và bên đào tạo tiêu thụ chúng theo tốc độ riêng của nó. Người điều phối theo dõi độ lệch phiên bản và kích hoạt làm mới trọng số, tối đa hóa việc sử dụng thiết bị.
Ở lớp dưới cùng, Echo được xây dựng trên Parallax (suy diễn dị dạng trong môi trường băng thông thấp) và các thành phần đào tạo phân tán nhẹ (ví dụ: VERL), dựa vào LoRA để giảm chi phí đồng bộ hóa giữa các nút, cho phép học tăng cường hoạt động ổn định trên các mạng dị dạng toàn cầu.
Grail: Học Tăng cường trong Hệ sinh thái Bittensor
Bittensor xây dựng một mạng lưới chức năng phần thưởng hiếm, không ổn định khổng lồ thông qua cơ chế đồng thuận Yuma độc đáo của nó.
AI Covenant trong hệ sinh thái Bittensor xây dựng một đường ống tích hợp theo chiều dọc từ đào tạo trước đến đào tạo sau RL thông qua SN3 Templar, SN39 Basilica và SN81 Grail. Trong số đó, SN3 Templar chịu trách nhiệm cho việc đào tạo trước mô hình cơ bản, SN39 Basilica cung cấp một thị trường sức mạnh tính toán phân tán, và SN81 Grail phục vụ như là "tầng suy diễn có thể xác minh" cho đào tạo sau RL, mang theo các quy trình cốt lõi của RLHF / RLAIF và hoàn thành tối ưu hóa vòng kín từ mô hình cơ bản đến chính sách đã được điều chỉnh.

GRAIL xác minh tính chính xác của các vòng RL và ràng buộc chúng với danh tính mô hình, cho phép RLHF mà không cần tin cậy. Nó sử dụng các thách thức xác định để ngăn chặn việc tính toán trước, lấy mẫu với chi phí thấp và cam kết để xác minh các vòng, cùng với việc điểm danh mô hình để phát hiện sự thay thế hoặc lặp lại—thiết lập tính xác thực từ đầu đến cuối cho các lộ trình suy diễn RL.
Mạng con của Grail thực hiện một vòng lặp sau đào tạo phong cách GRPO có thể xác minh: thợ đào tạo ra nhiều đường dẫn lý luận, người xác thực chấm điểm độ chính xác và chất lượng lý luận, và các kết quả bình thường được ghi trên chuỗi. Các bài kiểm tra công khai đã nâng cao độ chính xác MATH của Qwen2.5-1.5B từ 12.7% lên 47.6%, cho thấy cả khả năng chống gian lận và sự gia tăng khả năng mạnh mẽ; trong AI Covenant, Grail phục vụ như là lõi tin cậy và thực thi cho RLVR/RLAIF phi tập trung.
Fraction AI: Học Tăng cường Dựa trên Cạnh tranh RLFC
Fraction AI định hình lại sự điều chỉnh như Học Tăng cường từ Cạnh tranh, sử dụng việc gán nhãn trò chơi và các cuộc thi giữa các đại diện. Xếp hạng tương đối và điểm số của AI thẩm phán thay thế các nhãn người dùng tĩnh, biến RLHF thành một trò chơi đa tác nhân cạnh tranh liên tục.
Sự khác biệt Cốt lõi Giữa RLHF Truyền thống và RLFC của Fraction AI:
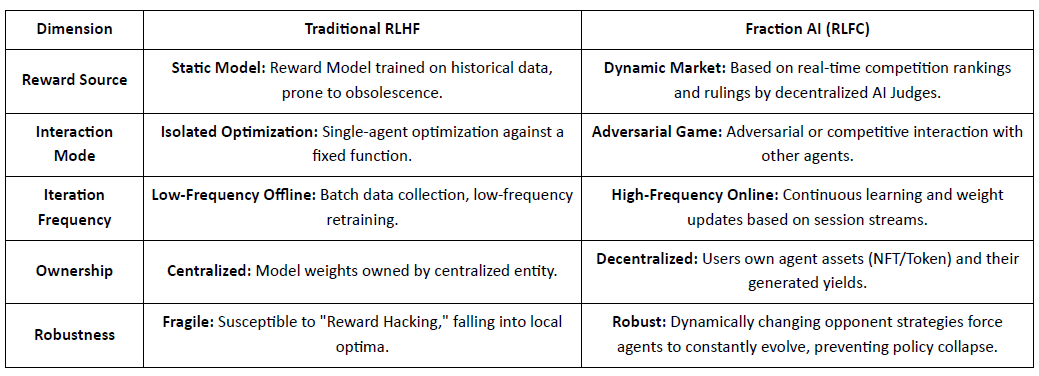
Giá trị cốt lõi của RLFC là phần thưởng đến từ những đối thủ và người đánh giá đang tiến hóa, không phải từ một mô hình đơn lẻ, giảm thiểu gian lận phần thưởng và bảo tồn sự đa dạng chính sách. Thiết kế không gian định hình động lực trò chơi, cho phép các hành vi cạnh tranh và hợp tác phức tạp.
Trong kiến trúc hệ thống, Fraction AI phân tách quá trình đào tạo thành bốn thành phần chính:
Đại lý: Các đơn vị chính sách nhẹ dựa trên các LLM mã nguồn mở, được mở rộng thông qua QLoRA với trọng số khác nhau cho các cập nhật chi phí thấp.
Không gian: Các môi trường miền nhiệm vụ cách ly nơi các đại lý phải trả phí để vào và kiếm phần thưởng bằng cách thắng cuộc.
Thẩm phán AI: Lớp phần thưởng ngay lập tức được xây dựng với RLAIF, cung cấp đánh giá phi tập trung, có thể mở rộng.
Bằng chứng về Học tập: Ràng buộc các cập nhật chính sách với các kết quả cạnh tranh cụ thể, đảm bảo rằng quá trình đào tạo có thể xác minh và chống gian lận.
Fraction AI hoạt động như một động cơ đồng tiến hóa giữa người và máy: người dùng hành động như những người tối ưu hóa meta hướng dẫn khám phá, trong khi các đại lý cạnh tranh để tạo ra dữ liệu sở thích chất lượng cao, cho phép tinh chỉnh thương mại mà không cần tin cậy.
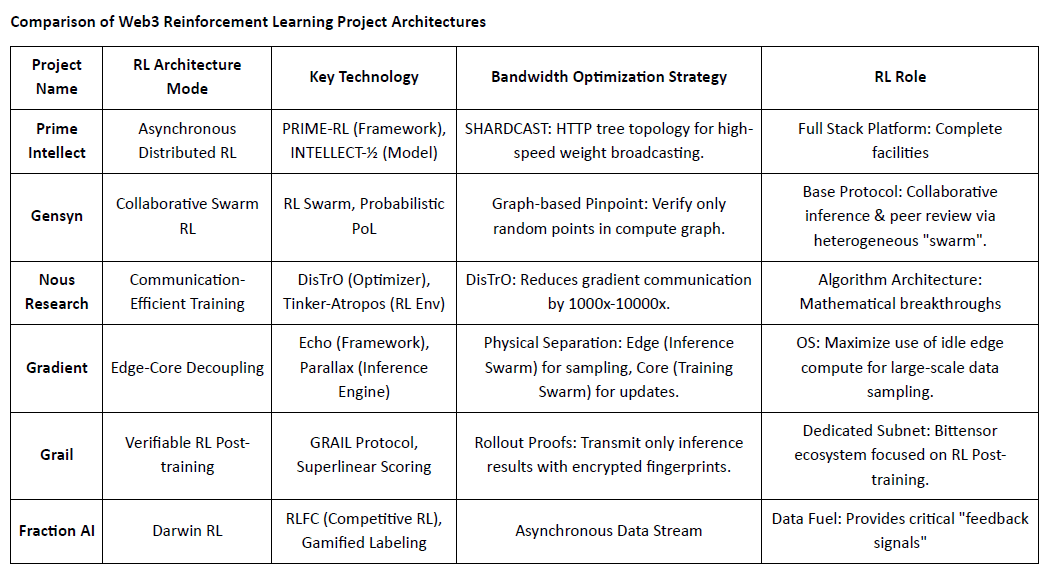
So sánh Kiến trúc Dự án Học Tăng cường Web3
V. Đường đi và Cơ hội của Học Tăng cường × Web3
Trong các dự án tiên phong này, mặc dù các điểm bắt đầu khác nhau, RL kết hợp với Web3 luôn hội tụ vào một kiến trúc “tách biệt–xác minh–khuyến khích” chung—một kết quả không thể tránh khỏi của việc điều chỉnh học tăng cường cho các mạng phân tán.
Các Tính năng Kiến trúc Tổng quát của Học Tăng cường: Giải quyết Các Giới hạn Vật lý Cốt lõi và Các Vấn đề Độ tin cậy
Tách rời các Vòng và Học (Tách biệt Vật lý giữa Suy diễn/Đào tạo) — Kiến trúc Tính toán Mặc định: Các Vòng giao tiếp thưa thớt, có thể song song được ủy quyền cho các GPU tiêu dùng toàn cầu, trong khi các cập nhật tham số băng thông cao được tập trung tại một vài nút đào tạo. Điều này đúng từ Actor–Learner không đồng bộ của Prime Intellect đến kiến trúc đàn đôi của Gradient Echo.
Độ tin cậy Được Đưa ra — Cơ sở hạ tầng: Trong các mạng không cần quyền, tính chính xác tính toán phải được đảm bảo một cách cưỡng bức thông qua toán học và thiết kế cơ chế. Các triển khai đại diện bao gồm PoL của Gensyn, TopLoc của Prime Intellect và xác minh mật mã của Grail.
Vòng Khuyến khích Được Token hóa — Tự điều chỉnh Thị trường: Cung cấp tính toán, tạo dữ liệu, phân loại xác minh và phân phối phần thưởng tạo thành một vòng kín. Các phần thưởng thúc đẩy sự tham gia, và Slashing ngăn chặn gian lận, giữ cho mạng ổn định và liên tục phát triển trong một môi trường mở.
Các Con đường Kỹ thuật Phân biệt: Các "Điểm Đột Phá" Khác nhau Dưới Kiến trúc Nhất quán
Mặc dù các kiến trúc đang hội tụ, các dự án chọn các chướng ngại kỹ thuật khác nhau dựa trên DNA của chúng:
Trường Đột phá Thuật toán (Nghiên cứu Nous): Giải quyết nút thắt băng thông của đào tạo phân tán ở cấp độ bộ tối ưu—DisTrO nén giao tiếp độ dốc xuống mức độ lớn, nhằm mục đích cho phép đào tạo mô hình lớn qua băng thông gia đình.
Trường Kỹ thuật Hệ thống (Prime Intellect, Gensyn, Gradient): Tập trung vào việc xây dựng "Hệ thống Thời gian Chạy AI" thế hệ tiếp theo. ShardCast của Prime Intellect và Parallax của Gradient được thiết kế để ép tối đa hiệu suất từ các cụm dị dạng dưới các điều kiện mạng hiện có thông qua các phương tiện kỹ thuật cực đoan.
Trường Chơi Thị trường (Bittensor, Fraction AI): Tập trung vào thiết kế Các Hàm Phần thưởng. Bằng cách thiết kế các cơ chế chấm điểm tinh vi, họ hướng dẫn các thợ đào tìm ra các chiến lược tối ưu một cách tự phát để thúc đẩy sự xuất hiện của trí thông minh.
Ưu điểm, Thách thức và Triển vọng Cuối cùng
Dưới mô hình Học Tăng cường kết hợp với Web3, các ưu điểm cấp hệ thống trước tiên được thể hiện trong việc viết lại cấu trúc chi phí và cấu trúc quản lý.
Thay đổi Chi phí: Đào tạo sau RL có nhu cầu không giới hạn về lấy mẫu (Vòng). Web3 có thể huy động sức mạnh tính toán toàn cầu dài hạn với chi phí cực thấp, một lợi thế chi phí khó cho các nhà cung cấp đám mây tập trung để cạnh tranh.
Sự Điều chỉnh Độc lập: Phá vỡ sự độc quyền của công nghệ lớn đối với giá trị AI (Điều chỉnh). Cộng đồng có thể quyết định "câu trả lời tốt là gì" cho mô hình thông qua việc bỏ phiếu Token, hiện thực hóa sự dân chủ hóa quản lý AI.
Đồng thời, hệ thống này phải đối mặt với hai ràng buộc cấu trúc:
Bức tường Băng thông: Mặc dù có những đổi mới như DisTrO, độ trễ vật lý vẫn hạn chế việc đào tạo đầy đủ các mô hình tham số siêu lớn (70B+). Hiện tại, Web3 AI chủ yếu bị giới hạn ở việc tinh chỉnh và suy diễn.
Gian lận Phần thưởng (Luật Goodhart): Trong các mạng có phần thưởng cao, thợ đào dễ bị "quá khớp" với các quy tắc phần thưởng (lừa đảo hệ thống) hơn là cải thiện trí tuệ thực. Thiết kế các hàm phần thưởng chống gian lận là một trò chơi vĩnh viễn.
Nhân viên Byzantine độc hại: chỉ đến việc thao túng và đầu độc có chủ đích các tín hiệu đào tạo để làm gián đoạn sự hội tụ mô hình. Thách thức cốt lõi không phải là thiết kế liên tục các hàm phần thưởng chống gian lận, mà là các cơ chế có tính chống đối.
RL và Web3 đang định hình trí thông minh thông qua các mạng vòng phân tán, phản hồi tài sản trên chuỗi, và các tác nhân RL theo chiều dọc với khả năng thu giá trị trực tiếp. Cơ hội thực sự không phải là một OpenAI phân quyền, mà là các mối quan hệ sản xuất trí thông minh mới—thị trường tính toán mở, phần thưởng và sở thích có thể quản lý, và giá trị chia sẻ giữa các nhà đào tạo, người điều chỉnh và người dùng.
Tuyên bố miễn trừ trách nhiệm: Bài viết này đã được hoàn thành với sự hỗ trợ của các công cụ AI ChatGPT-5 và Gemini 3. Tác giả đã nỗ lực hết sức để hiệu đính và đảm bảo thông tin chính xác và xác thực, nhưng vẫn có thể còn thiếu sót. Xin hãy thông cảm. Đặc biệt lưu ý rằng thị trường tài sản tiền điện tử thường xuyên trải qua sự khác biệt giữa các yếu tố cơ bản của dự án và hiệu suất giá trên thị trường thứ cấp. Nội dung của bài viết này chỉ nhằm mục đích tích hợp thông tin và trao đổi học thuật/nghiên cứu và không cấu thành bất kỳ lời khuyên đầu tư nào, cũng như không nên được coi là khuyến nghị mua hoặc bán bất kỳ token nào.