

Walrus Protocol media hosting is the moment protocols realize they were leaning on CDN comfort the whole time.
A profile picture goes viral. A mint page gets linked by an influencer. A game client drops an update and every launcher pulls the same files in the same five minutes. Nothing about the content is "hard'. It is just hot, yeah.
In that 'hot' moment, decentralized origins get stressed first... retrieval load, not storage itself.
With a CDN, popularity is mostly a routing problem. Cache fills. Edges serve. Your origin sees a smoothed curve and you get to call it "stable" even when it is just buffering the pain somewhere else.
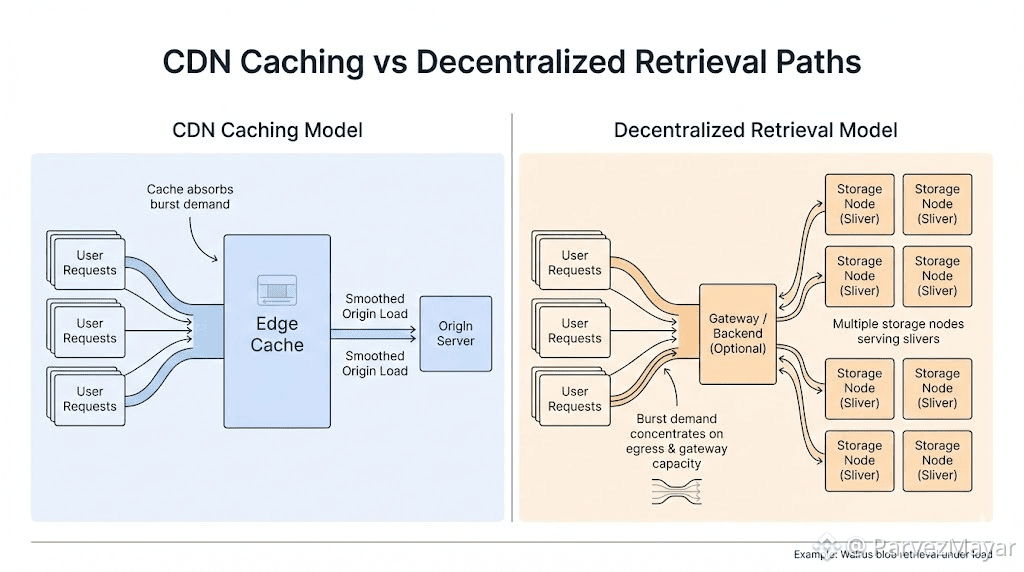
On Walrus though, the blob can be there and still behave like it is not.
"there' isn't a single origin with a global front door. It's storage nodes serving slivers... plus whatever retrieval path your users hit through gateways and backends you control (or don't). Under a spike the system does not fail like a database. It fails like bandwidth. Same asset... same few minutes too many concurrent reads and suddenly the bottleneck isn't your app code or your contract logic. It is egress. Pipes. Cold disks. The stuff nobody puts on the mint page.
Many protocol teams carry a caching assumption like it's weather. First request is slow then the internet "handles it". They don't spec it. They don't budget it. It is just how things usually feel to be honest.
Walrus makes you name all of this.
Where is your cache when something gets hot. Who pays for it. Does it live inside your application backends because you quietly became the CDN. Is it a gateway layer you run and scale on demand. Is it pushed to clients. Or is it the vague hope that "the network will absorb it', which is a nice sentence right up until the first spike turns into a dogpile of retries.
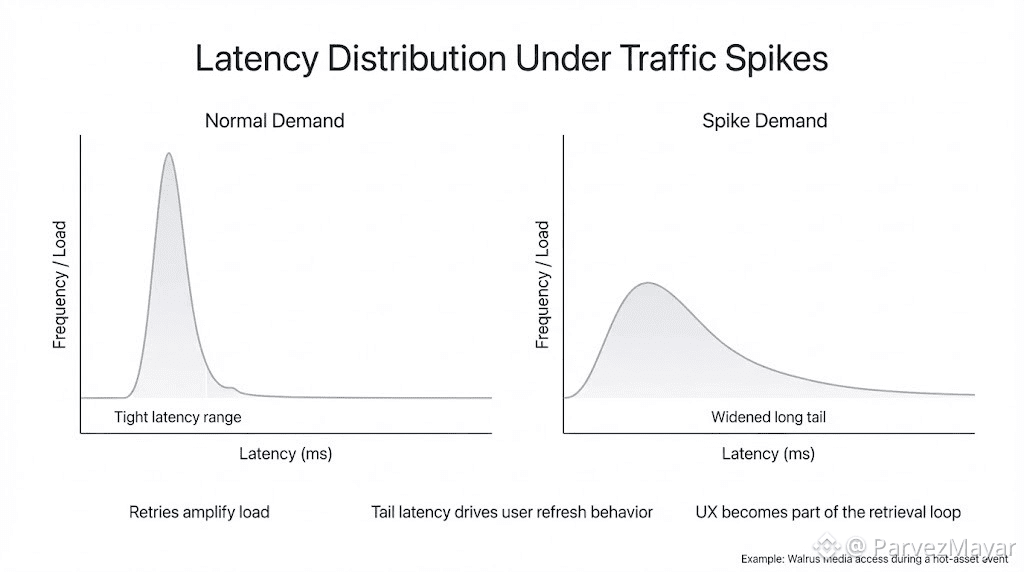
And the first thing that breaks isn't availability. It is the shape of latency actually.
The long tail widens. A few users get instant loads. A few users get spinners. Somebody retries. Somebody refreshes. Now you've manufactured extra load while panicking about load. If the asset is referenced by something irreversible reveal timing, paid access unlock, "this token now shows the art", your support inbox becomes part of the retrieval path.
PoA doesn't save you in this. PoA is the receipt that the blob crossed the boundary and the system took the obligation. Useful. Necessary. Still not the same as "this will be fast when 40,000 people hit it at once".
Hot content is the part people skip when they talk about decentralized media hosting. Ten thousand blobs can sit quietly for weeks and nothing matters. One blob gets hot and suddenly it's the only thing anyone associates with your project.
So you build with the ugly map in your head.
You pre-warm the obvious spike assets. You decide whether your backend is allowed to relay (and how much). You cap retries so users do not turn impatience into bandwidth load. You treat "first fetch" like a real operational event.. not a warm-up lap. You watch behavior across epochs too, because churn plus a spike is where things get sharp fast.
Operator behavior leaks into app UX in exactly the way teams don't like. Nodes do not have infinite egress. They're not obligated to love your viral moment. They Are running boxes, paying bills, making tradeoffs when traffic gets weird. A spike looks like demand... sure. It also looks like cost arriving all at once.
If your design assumes the network will absorb popularity the way a CDN does, you're borrowing a comfort you didn't buy.
Walrus can store the bytes. Fine.
The question is whether your media flow can take "hot" without you accidentally becoming the origin again quietly, expensively, in the five minutes that decide whether your mint feels smooth or cursed.@Walrus 🦭/acc

