

Il messaggio sull'incidente su Dusk inizia come fanno sempre i messaggi rassicuranti... "Nessuna perdita di vivacità".
I blocchi continuavano ad arrivare. La finalità continuava a stabilirsi. Le attestazioni continuavano ad arrivare come un orologio... un'esportazione pulita che puoi collegare a un ticket e andare avanti. L'Attestazione Sintetica su Dusk ha fatto ciò che doveva fare e la macchina del Proof-of-Stake basata sul comitato sembrava... professionale. Pulita. Prevedibile, giusto?
Questa è la parte che dovrebbe preoccuparti.
Ho partecipato a chiamate in cui l'unico 'sintomo' era la velocità con cui tutti erano d'accordo. Gli stessi dashboard, gli stessi grafici e lo stesso verdetto. Quell'allineamento che sembra maturità fino a quando non ti ricordi cosa rappresenta veramente... un comportamento correlato che indossa un completo.
Sul Dusk Foundation, il sortition deterministico più un ciclo stretto di proposta, validazione e ratifica fa arrivare gli esiti velocemente... e fa convergere velocemente anche le "migliori pratiche". È tutto a posto fino a quando tutti ottimizzano per la stessa versione di "sicuro". Nei circoli istituzionali, "sicuro" significa di solito standard.
Stesso build del client. Stessi default di configurazione. Stesso stack di monitoraggio. Stesso approccio alla sincronizzazione dell'orologio... stesso pool NTP, la metà del tempo. Le finestre di aggiornamento scelte negli stessi orari a basso traffico durante la rotazione del comitato. Runbook scritti per soddisfare i controlli operativi interni. E la stessa paura che si nasconde sotto tutto ciò, non detta: non essere l'eccezione.
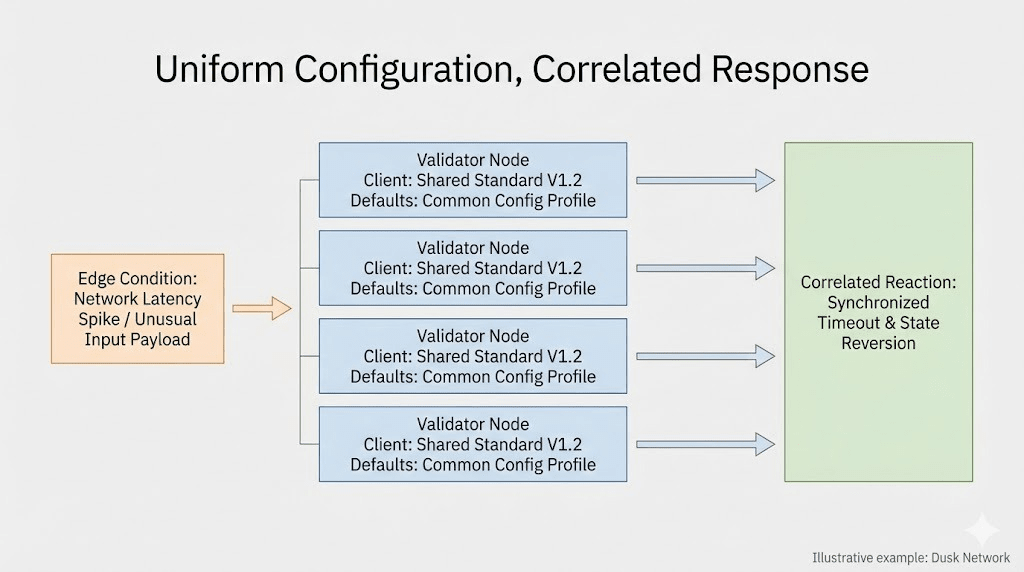
Nessuno lo chiama monocultura. Lo chiamano standard.
Poi appare improvvisamente una piccola condizione particolare. Non un attacco. Non un fallimento drammatico. Un problema di dipendenza, una partizione di rete, uno scostamento dell'orologio, un aggiornamento di routine che si comporta leggermente diversamente sotto carico. Il tipo di cosa che ti aspetti che un comitato decentralizzato Dusk possa assorbire grazie alla diversità.
Ma il comitato non diversifica la sua risposta. Si converte.
Le azioni protettive vengono attivate nello stesso momento. I limiti vengono applicati nella stessa direzione. La logica di fallback si attiva in sincronia. Gli operatori seguono lo stesso piano di emergenza perché è così che dovrebbe apparire la professionalità. Ottieni un movimento coordinato senza coordinamento.
La catena sembra ancora sana. La finalità arriva ancora. Dall'esterno, puoi indicare la "vitalità in caso di fallimenti parziali" su Dusk ed essere tecnicamente corretto. All'interno del comitato Dusk, però, sta accadendo qualcos'altro... il sistema non sta più testando la competenza individuale dei validatori. Sta testando se le assunzioni condivise siano sbagliate.
E gli incentivi si invertono in modo noioso.
I delegatori e le istituzioni ricompensano i validatori che sembrano più uniformi perché l'uniformità è comprensibile. L'uniformità è accettabile. L'uniformità è facile da approvare. Un validatore che utilizza uno stack diverso, ritarda gli aggiornamenti tra gli epoch o rifiuta i default comuni potrebbe essere più sicuro per il comitato Dusk... ma è più difficile giustificare in un controllo operativo. Perciò gli incentivi si comprimono verso l'omogeneità.
E una volta che ciò accade, la finalità deterministica diventa un po' ingannevole. Ti dice che la rete si è finalizzata. Non ti dice quanto il comitato si sia avvicinato a esprimere un singolo errore condiviso come risultato verificato dal consenso.
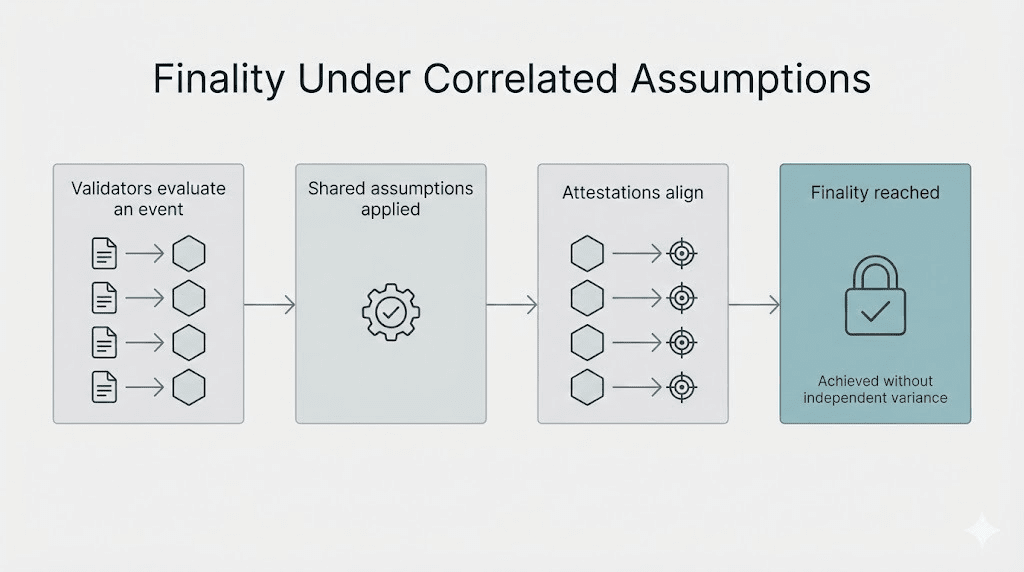
Puoi avere attestazioni pulite su Dusk e comunque trovarsi in un rischio correlato, onestamente.
I modi di emergenza esistono quando le cose diventano strane. Ma "strano" non annuncia sempre un'interruzione. A volte "strano" è un comitato che si comporta come un solo operatore perché tutti stanno eseguendo lo stesso piano. Il sistema non sta fallendo rumorosamente.
Si sta indebolendo silenziosamente.
Puoi vedere il residuo nella politica prima di vederlo nei dati di telemetria. Le regole non scritte iniziano a formarsi.
"Noi deleghiamo solo a validatori con lo stack standard". "Non vogliamo configurazioni sperimentali nel comitato"... "Aggiorniamo quando tutti aggiornano". "Se qualcosa va storto, almeno eravamo allineati."
Quell'ultima frase è la trappola. L'allineamento sembra bene. Passa il controllo.
La Fondazione Dusk non ha bisogno che i validatori siano eroici, in realtà. Ha bisogno che siano abbastanza sconnessi da permettere al comitato di sopravvivere a cieche condivise. Se la professionalità continua a essere definita come comportamento identico, il rischio di coda non scompare. Si sposta semplicemente in quel posto che i dashboard non misurano bene: la decisione sincronizzata.
E il giorno in cui tutto questo diventa fondamentale, il postmortem non dirà "i validatori hanno sotto-performato". Sarà scritto come una nota che passa l'approvazione e spiega nulla.
"Procedura seguita". "Runbook eseguiti." "Il comitato ha risposto correttamente."
E la settimana prossima c'è una nuova voce nella checklist che nessuno discute... resta sullo stack standard..
