
Most storage systems sell comfort. You upload something, you get a link, and the system reassures you that your data is safe. Under the surface, the promise is simple and human: nothing bad will happen. But anyone who has spent time around open networks knows how fragile that promise can be. Nodes go offline without warning. Operators disappear. Incentives change. What looks stable on a dashboard slowly degrades in real life. This is the quiet gap that Walrus steps into. Not by offering louder guarantees, but by reframing what storage actually means. In Walrus, storage is not a passive act. It is an ongoing, provable responsibility. Something that must be demonstrated again and again, especially when the network is under pressure.
Traditional storage, even in decentralized form, often treats failure as an exception. Systems are optimized for calm conditions and hope that redundancy will absorb shocks when chaos arrives. Walrus starts from the opposite assumption. Instability is normal. Nodes will drop. Hardware will fail. Some participants will underperform. Instead of reacting with expensive, network-wide repair storms, Walrus is designed to respond with precision. When something goes missing, the system focuses only on what needs fixing. Recovery becomes targeted rather than dramatic. This shift matters more than it first appears. It turns resilience from an emergency response into a steady background process. The network stays calm because it expects stress and budgets for it in advance.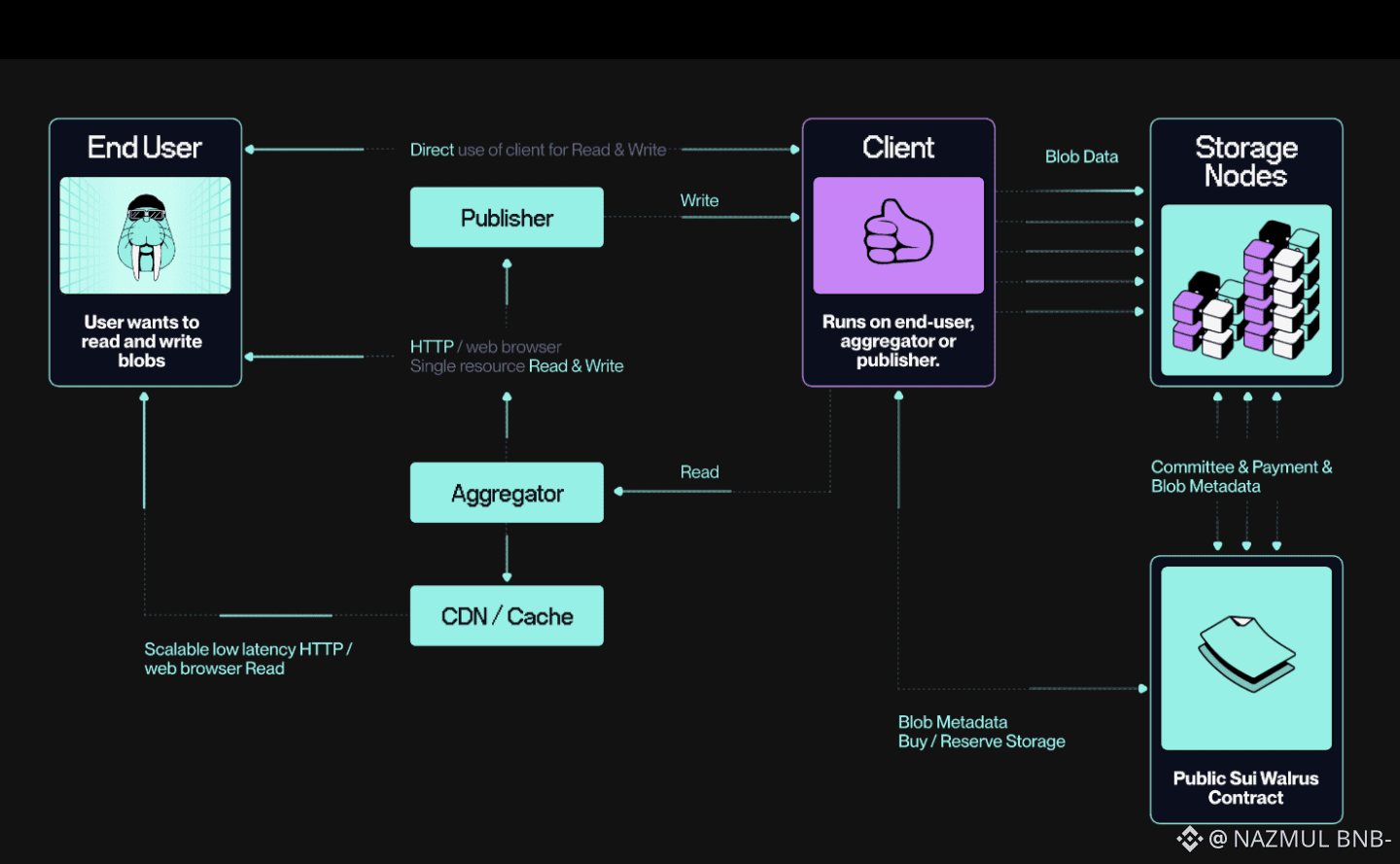
A lot of attention around Walrus focuses on its encoding approach, often described as a cost or efficiency breakthrough. That framing misses the deeper point. Efficiency here is not about being cheaper in good times. It is about being survivable in bad ones. Walrus breaks data into encoded pieces that can be distributed across many nodes in a way that minimizes the amount of work needed to restore availability. If a few pieces disappear, the system does not need to reshuffle everything. It reconstructs only what is missing. This is the difference between repairing a cracked tile and rebuilding the whole floor. In open networks, that difference determines whether recovery is sustainable or self-destructive.
What makes this approach feel unusually grounded is how little it relies on trust or social signaling. Walrus does not ask users to believe that the network is healthy. It asks nodes to prove it. Availability is checked continuously through measurable events, not occasional audits or vague claims. Over time, this creates a rhythm where good behavior is rewarded because it is observable, and bad behavior becomes expensive because it is visible. The system does not need dramatic punishments. It simply aligns incentives so that staying reliable is the easiest path. This is a quiet kind of discipline, but also a powerful one.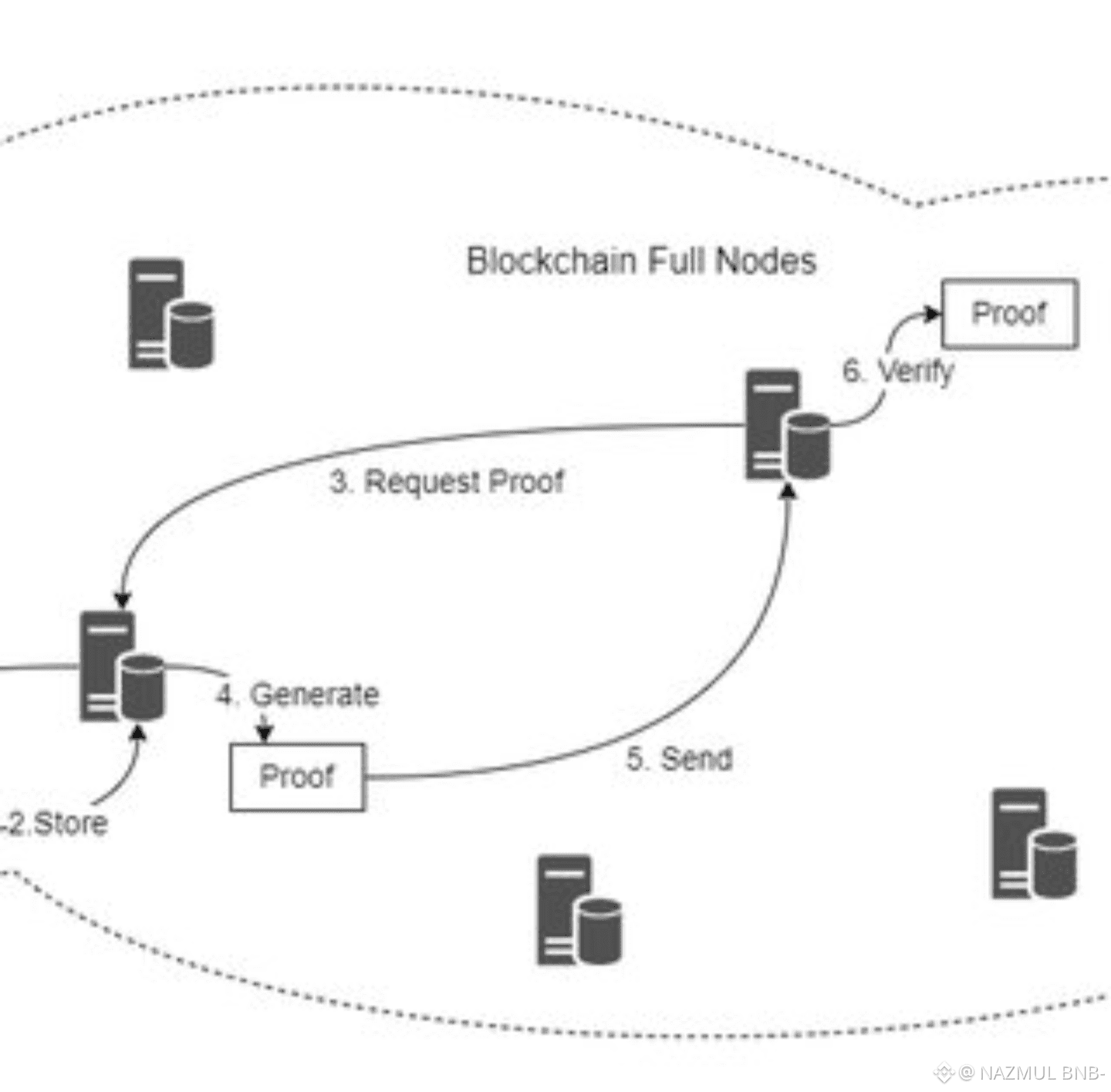
Seen through this lens, the WAL token starts to make more sense. It is tempting to view any token as branding or speculation, but here it functions more like fuel for a market around availability. Storage, repair, and verification all carry real costs. The token coordinates who pays for reliability and who earns by providing it. Instead of pretending that long-term data availability is free, Walrus prices it honestly. That honesty may not sound exciting, but it is rare. It allows builders to reason about trade-offs clearly. How much durability do I need? For how long? Under what conditions? These questions become economic choices rather than marketing slogans.
There is also something culturally unusual about Walrus. It does not seem interested in winning attention battles. Its design choices suggest a team more concerned with how the system behaves on a bad day than how it looks on a good one. That mindset shows up everywhere. In the way repairs are scoped. In the way availability is proven. In the way incentives are stretched over time instead of front-loaded. The result is a protocol that feels less like a pitch and more like infrastructure. Something you do not talk about much once it works, but quietly rely on when things get messy.
The honest takeaway is not that Walrus will replace every storage solution or that it solves every problem. It is that Walrus walks a narrow path many projects avoid. It treats failure as the default state, not the exception. It values measurable behavior over promises. And it optimizes for recovery under stress rather than performance under ideal conditions. These choices are easy to underestimate because they do not produce flashy demos. But over time, they attract a certain kind of builder. The ones who have been burned before. The ones who care less about narratives and more about whether their data will still be there when the network is not feeling generous.
In a space where so much energy is spent on appearances, Walrus is focused on responsibility. That focus may never dominate headlines. But it has a way of quietly compounding. And often, those are the systems that matter most.

